
DataCore Software Unveils K8s-Native Storage Platform
At the KubeCon + CloudNativeCon Europe 2022 event, DataCore Software today launched a container storage platform based on OpenEBS, a container storage platform that runs natively in userspace on Kubernetes.
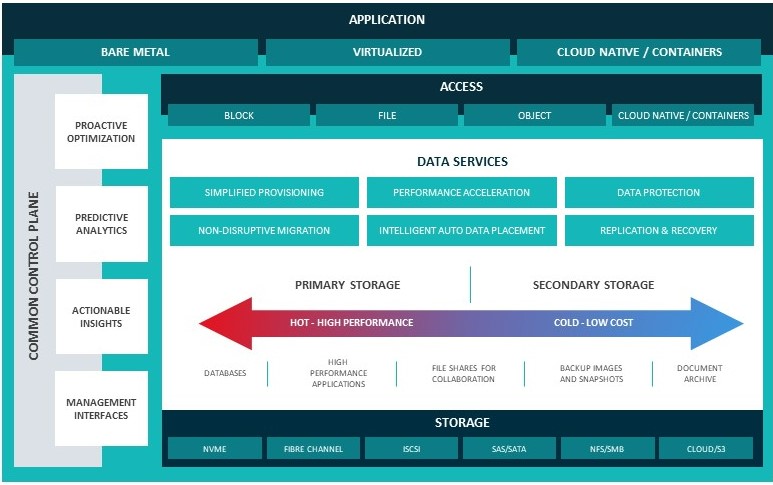
DataCore Software CEO Dave Zabrowski says DataCore Bolt is based on a microservices architecture that, unlike legacy storage platforms that rely on plug-ins, natively scales up and down within a Kubernetes cluster. It also makes it simpler to provision and replicate storage across multiple Kubernetes pods while support for NVMe-oF/TCP infrastructure ensures high levels of I/O throughput, he adds.

OpenEBS was originally developed by MayaData, which was acquired last year by DataCore Software. As more stateful applications are deployed on Kubernetes clusters the need for storage software that is specifically designed to run natively in those environments is becoming more apparent, says Zabrowski.
DataCore Bolt takes advantage of a composable, disaggregated architecture that enables IT to take advantage of advances in the latest commodity storage to reduce overall costs, he adds. That approach also makes it simpler for IT teams to incorporate DataCore Bolt within a larger DevOps workflow, notes Zabrowski.
Other benefits include the ability to ensure portability of storage services by removing kernel/OS dependencies, increase observability into storage behavior and higher levels of resiliency, adds Zabrowski.
Interest in deploying stateful applications on Kubernetes clusters has risen because many IT teams don’t want to have to depend on external storage systems managed by a separate IT administrator. Storage, instead, is managed within the context of a converged platform. Kubernetes provides access to storage using persistent volumes (PV). This makes it possible to access data far beyond the lifespan of any given pod. Kubernetes volumes allow users to mount storage units to expand how much data they can share between nodes. Regular volumes will still be deleted if and when the pod hosting that particular volume is shut down. The permanent volume, however, is hosted on its own pod to ensure data remains accessible. Upon creation, the PV is bound to the pod that requested the PVC. IT teams can then manage storage in Kubernetes via a PersistentVolumeClaim (PVC) function to request storage; a PersistentVolume (PV) to manage storage life cycle and a StorageClass function that defines different classes of storage services.
It’s not likely that container storage platforms that run natively on Kubernetes will supplant the need for external storage systems. Many IT teams prefer to deploy stateless applications that eventually store data on those external systems. However, as IT teams start to deploy microservices-based applications at scale on Kubernetes clusters, there will be a need for storage platforms that are designed to scale up or down as demand for data access within highly dynamic IT environments changes.
In the meantime, IT teams are likely to find themselves deploying both storage platforms that run natively on Kubernetes as well as plugins for external systems to access legacy data. The challenge is going to be determining which platform to use, and when, based on the requirements of various classes of applications.
