
Stop Wasting GPU Budget: Autoscaling AI Inference on Kubernetes with KEDA
The rush to deploy Large Language Models (LLMs) and generative AI has created a massive infrastructure bottleneck. Platform engineering teams are spinning up expensive GPU node pools on Kubernetes, but they are quickly realizing a painful truth: standard Kubernetes scaling mechanisms were not built for AI.
When an AI inference service experiences a sudden spike in requests, standard Horizontal Pod Autoscaling (HPA) usually fails to respond appropriately. HPA relies on CPU and system memory metrics. However, deep learning workloads are bottlenecked by GPU Compute (SM

Utilization) and GPU VRAM Allocation. A pod’s CPU usage might look completely idle while its GPU queue is overflowing, leading to severe latency, dropped requests, and a poor user experience.
To solve this, we must transition from resource-based scaling to event-driven, hardware-aware scaling using KEDA (Kubernetes Event-driven Autoscaling).
The Architecture of GPU-Aware Scaling
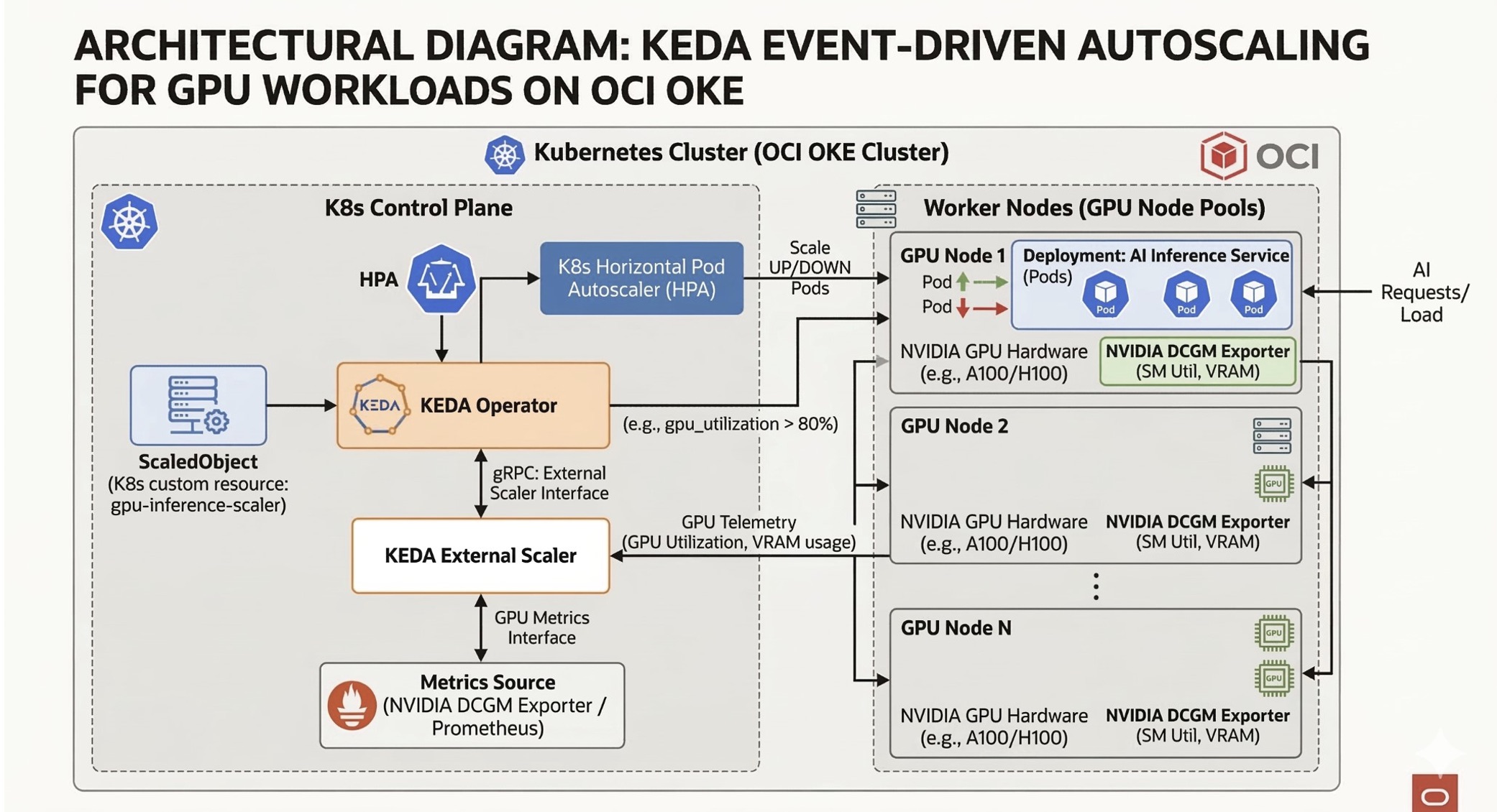
KEDA is a CNCF-graduated project that allows Kubernetes to scale deployments based on external metrics. While KEDA has built-in scalers for message queues like Kafka or RabbitMQ, scaling based on raw GPU telemetry requires bridging the gap between hardware exporters (like NVIDIA DCGM) and the Kubernetes control plane.
To implement this on high-performance infrastructure—such as Oracle Kubernetes Engine (OKE) with bare-metal GPU shapes—we need an architecture that consists of three layers:
- The Telemetry Layer: Exposing GPU SM utilization and memory allocation metrics from the physical hardware.
- The Translation Layer: A KEDA External Scaler that ingests those specific hardware metrics and translates them into a format the KEDA metrics server understands.
- The Execution Layer: The KEDA Operator triggering the scaling of the inference pods, including scaling to zero when the service is idle to eliminate cloud compute costs.
Implementing a Custom GPU Scaler
To bridge the translation gap, I recently open-sourced the keda-gpu-scaler (available on GitHub at pmady/keda-gpu-scaler)), an external scaler designed specifically to feed GPU telemetry into KEDA.
Instead of writing complex Prometheus› queries to feed into HPA, the external scaler simplifies the deployment. Once the scaler is deployed to your cluster, you can configure a standard KEDA ScaledObject to target your AI inference deployment.
Here is how you configure the cluster to scale an LLM engine whenever GPU utilization exceeds 80%:

The Cost-Saving Power of “Scale to Zero”
The most critical line in the YAML above is minReplicaCount: 0.
Standard HPA cannot scale a deployment down to zero. If you have a generative AI microservice that is only used during business hours, standard Kubernetes will keep at least one GPU pod running 24/7, burning thousands of dollars a month in idle compute.
By utilizing KEDA with a custom GPU scaler, the cluster can completely terminate the AI workloads during off-hours, freeing up those expensive GPU nodes for asynchronous batch processing or model training.
Conclusion
As AI transitions from the research phase to enterprise production, platform engineering teams must apply the same rigorous infrastructure automation to GPUs that we have traditionally applied to CPUs. By integrating custom hardware telemetry with KEDA, organizations can ensure their AI services remain highly available during traffic spikes without paying for idle silicon when demand drops.
