
Rediscovering RocksDB – Embedded Storage in Cloud-Native Applications
For years, cloud-native architecture conversations have revolved around managed databases, distributed caches and scalable storage services. As applications moved into Kubernetes, many teams adopted a simple rule: If data needs to be stored, send it to a centralized service.
This approach works well for many workloads. It also introduces a hidden cost. Every read and write becomes a network operation.

As systems become increasingly distributed, engineers often discover that network latency, storage costs and operational complexity grow faster than expected. In many cases, applications are not struggling because they lack storage; they are struggling because there is too much distance between computation and data.
This is one reason RocksDB continues to appear inside some of the world’s largest infrastructure systems.
Originally developed at Facebook and built on top of LevelDB, RocksDB is an embedded key-value store designed for fast local storage. Unlike a traditional database server, RocksDB runs inside the application process itself. There is no separate database service to deploy, scale, patch or manage.
At first glance, this might seem like a step backward in a world dominated by managed services. In practice, it often solves a different class of problems.
Consider a Kubernetes-based platform responsible for processing millions of events each day. Every pod needs access to temporary state, checkpoints, metadata and processing context.
Sending every update to a remote database can quickly become expensive from both a latency and an operational perspective.
A common architecture looks like this:
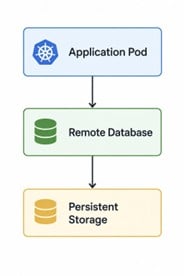
This architecture is simple and familiar. It is also dependent on network round trips for every operation.
Now consider a different approach:
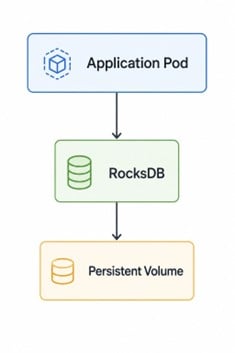
The application interacts with local storage directly. Reads and writes occur within the same pod. Network traffic reduces, latency decreases and the system becomes less dependent on external services for short-lived operational state.
This pattern has become increasingly common in stream processing platforms, stateful event processing systems and distributed data infrastructure.
Apache Kafka Streams is perhaps the most widely known example. Under the hood, Kafka Streams uses RocksDB to maintain local state stores. Instead of repeatedly querying external systems, processing nodes keep state close to computation. This significantly improves throughput while reducing network overhead.
Flink takes a similar approach. Large-scale stateful stream processing requires efficient local storage, and RocksDB has become a common back end for managing operator state. The lesson extends beyond stream processing.
Many cloud-native platforms require temporary state that does not necessarily belong in a centralized database.
Examples include:
- Workflow checkpoints
- Session metadata
- Processing queues
- Intermediate computation results
- State machine transitions
- Caching layers
- Event processing offsets
These workloads often benefit from storage that is local, fast and operationally simple.
One cloud-native team I worked with initially stored workflow execution state inside a centralized database cluster. The architecture functioned correctly, but latency increased as workloads grew. Most state existed for only a few minutes before being discarded.
Moving short-lived operational state closer to processing nodes reduced database load and improved responsiveness without changing the overall workflow design.
The code required to work with RocksDB is surprisingly straightforward.
RocksDB Db = RocksDB.open(“/data/state”);
db.put(
“workflow-123”.getBytes(), “RUNNING”.getBytes()
);
byte[] state =
db.get(“workflow-123”.getBytes());
The simplicity is part of the appeal. There is no server configuration, connection pooling or network dependency. The application reads and writes directly against local storage.
Of course, RocksDB is not a replacement for every database.
If an application requires complex relational queries, multi-user access patterns, SQL reporting or centralized governance, a traditional database remains the better choice.
Likewise, RocksDB does not eliminate the need for object storage, distributed databases or cloud-native data platforms.
Its value comes from serving a specific role exceptionally well. RocksDB excels when data needs to stay close to computation.
As cloud-native architectures continue to evolve, many engineering teams are discovering that not every storage problem requires another distributed service. Sometimes the fastest storage layer is the one already running inside the application.
The industry has spent years moving everything toward centralized platforms. RocksDB represents a reminder that locality still matters.
In many modern systems, performance is not limited by storage capacity. It is limited by the distance between data and the code trying to use it.
This simple observation explains why RocksDB continues to be relevant in a cloud-native world.
