
Red Hat Advances Container Storage
Red Hat has moved to make storage a standard element of a container platform with the release of version 3.10 of Red Hat OpenShift Container Storage (OCS), previously known as Red Hat Container Native Storage.
Irshad Raihan, senior manager for product marketing for Red Hat Storage, says Red Hat decided to rebrand its container storage offering to better reflect its tight integration with the Red Hat OpenShift platform. In addition, the term “container native” continues to lose relevance given all the different flavors of container storage that now exist, adds Raihan.

The latest version of the container storage software from Red Hat adds arbiter volume support to enable high availability with efficient storage utilization and better performance, enhanced storage monitoring and configuration via the Red Hat implementation of the Prometheus container monitoring framework, and block-backed persistent volumes (PVs) that can be applied to both general application workloads and Red Hat OpenShift Container Platform (OCP) infrastructure workloads. Support for PVs is especially critical because to in the case of Red Hat OCS organizations can deploy more than 1,000 PVs per cluster, which helps to reduce cluster sprawl within the IT environment, says Raihan.
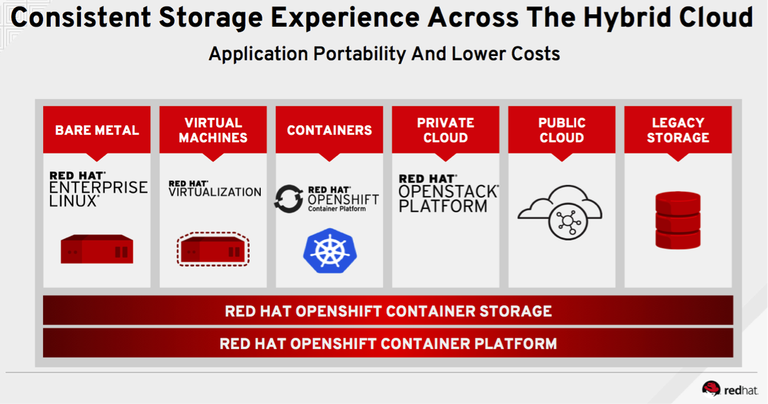
Raihan says Red Hat supports two types of OCS deployments that reflect the changing nature of the relationship between developers and storage administrators. A converged approach enables developers to provision storage resources on a cluster, while the independent approach makes OCS available on legacy storage systems managed by storage administrators. In both cases, storage administrators still managed the underlying physical storage. But in the case of the converged approach, developers can provision storage resources on their own as part of an integrated set of DevOps processes, he says.
Raihan adds that developers are also pushing their organizations toward the converged approach because of the I/O requirements of containerized applications. That approach also allows organizations to rely more on commodity storage rather than having to acquire and license software for an external storage array, he says, noting the approach also enables IT organizations to extend the skillsets of a Linux administrator instead of having to hire a dedicated storage specialist.
Longer term, Raihan says it’s now only a matter of time before DevOps processes and an emerging set of DataOps processes begin converging. Data scientists are driving adoption of DataOps processes to make it easier for applications to access massive amounts of data. In time, those processes will become integrated with applications being developed that in most cases are trying to access the same data, says Raihan.
As adoption of container continues to mature across the enterprise it’s clear that storage issues are now on the cusp of being addressed. Stateful applications based on containers require high-speed access to multiple forms of persistent storage. Sometime that storage may reside locally or in a public cloud. Regardless of where that data resides, however, the amount of time it takes to provision access to that data is no longer an acceptable bottleneck within the context of larger set of DevOps processes.
