
Evolving Kubernetes and GKE for Gen AI Inference
The unique challenges of AI, including large models, the need for specialized hardware, request/response patterns and their impact on scaling, demand fundamental changes to how container orchestration works. Over the past ten years, Kubernetes has become the leading platform for deploying cloud-native applications and microservices, backed by an extensive community and boasting a comprehensive feature set for managing distributed systems. Google is joining forces with partners like Red Hat to engineer these foundational improvements directly into the Kubernetes open-source project. This community-driven effort is focused on making Kubernetes “AI-aware” at its core, tackling critical areas like intelligent scheduling, standardized benchmarking and AI-aware routing. Also, the entire ecosystem benefits from a more robust and efficient platform for AI.
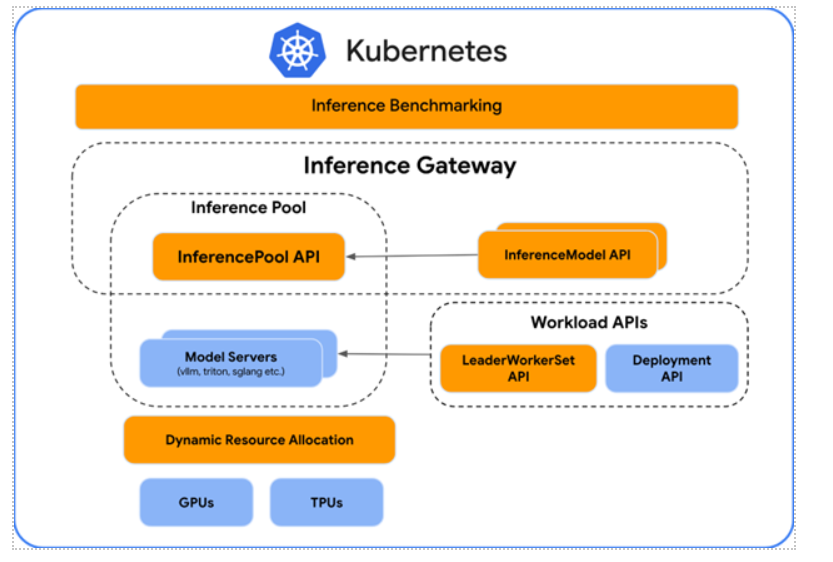

The open-source work lays the groundwork for new GKE features, giving you a differentiated implementation of all the Kubernetes primitives. Let’s dive into what this means for you.
Simplifying Deployment With GKE Inference Quickstart
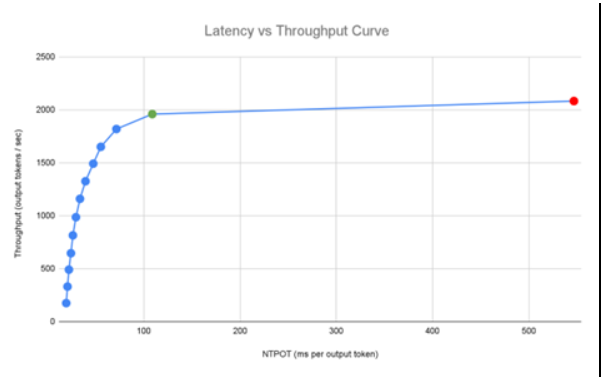
The journey to production for an AI model can be fraught with complexities, from selecting the right hardware accelerators to configuring the optimal serving environment. GKE Inference Quickstart is a new feature designed to streamline this entire process. The backend for Quickstart is an extensive benchmark database maintained by Google and generates latency vs throughput curves for every new model and accelerator configuration. The benchmarking system is also based on a standard inference-perf project in Kubernetes OSS.
By providing pre-configured and optimized setups, Inference Quickstart takes the guesswork out of deploying your models. It helps you make data-driven decisions on the most suitable accelerators for your specific needs, whether it’s GPUs or TPUs. This not only accelerates the time-to-market for your AI applications but also ensures that you are starting with a foundation that is built for performance and efficiency.
Image 1. A benchmarked latency vs throughput curve stored in the Quickstart database
Unlocking the Power of TPUs for Inference
Google’s TPUs have long been a cornerstone of its internal AI development, offering exceptional performance and cost-efficiency for machine learning workloads. Now, GKE is making it easier than ever to leverage these benefits for your own inference tasks.
With the new GKE TPU serving stack, you can seamlessly deploy your models on TPUs without the need for extensive code modifications. A key highlight is the support for the popular vLLM library on TPUs, allowing seamless interoperability across GPUs and TPUs. By opening up the power of TPUs for inference on GKE, Google is providing a compelling option for organizations looking to optimize their price-to-performance ratio for demanding AI workloads.
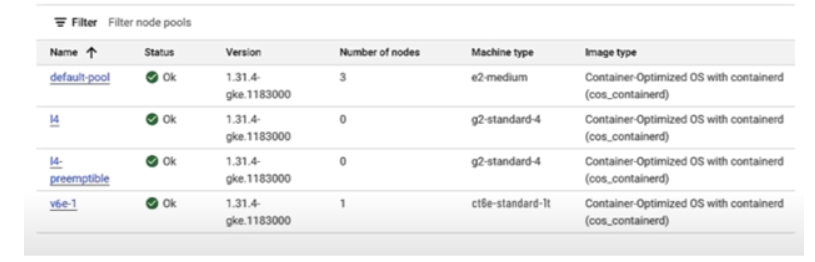
Image 2. A GKE deployment using both L4 GPU and v6e TPUs showcasing seamless portability
AI-Aware Load Balancing with GKE Inference Gateway
Unlike traditional load balancers that distribute traffic in a round-robin fashion, the Inference Gateway is intelligent and “AI-aware.” It understands the unique characteristics of generative AI workloads, where a simple request can result in a lengthy, computationally intensive response.
The Inference Gateway intelligently routes requests to the most appropriate model replica, taking into account factors like the current load and the expected processing time, which is proxied by the KV cache utilization. This prevents a single, long-running request from blocking other, shorter requests, a common cause of high latency in AI applications. The result is a dramatic improvement in performance and resource utilization.
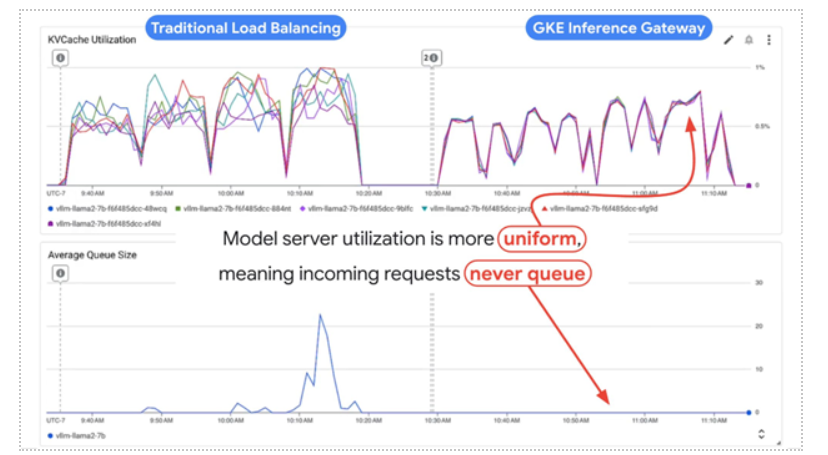
Image 3. Metrics without and with Inference Gateway, showcasing relative performance gains
The impact of this intelligent load balancing is striking, leading to:
- Up to a 60% reduction in tail latency: This means a more responsive and consistent experience for your users.
- Up to a 40% increase in throughput: You can serve more requests with the same infrastructure, maximizing your investment.
What This Means for You
The combination of foundational improvements in open-source Kubernetes and powerful, managed solutions on GKE represents a significant leap forward for any organization working with generative AI. The benefits are clear:
- Lower Total Cost of Ownership (TCO): By optimizing resource utilization and reducing infrastructure waste, you can significantly lower the cost of running your AI applications.
- Enhanced User Experience: Reduced latency translates to faster response times, keeping your users engaged and satisfied.
- Increased Developer Velocity: By simplifying deployment and management, your teams can focus on building innovative AI features rather than wrestling with infrastructure complexities.
