
Black Box Testing APIs in Microservices: Why Your Tests Pass but Your System Still Fails
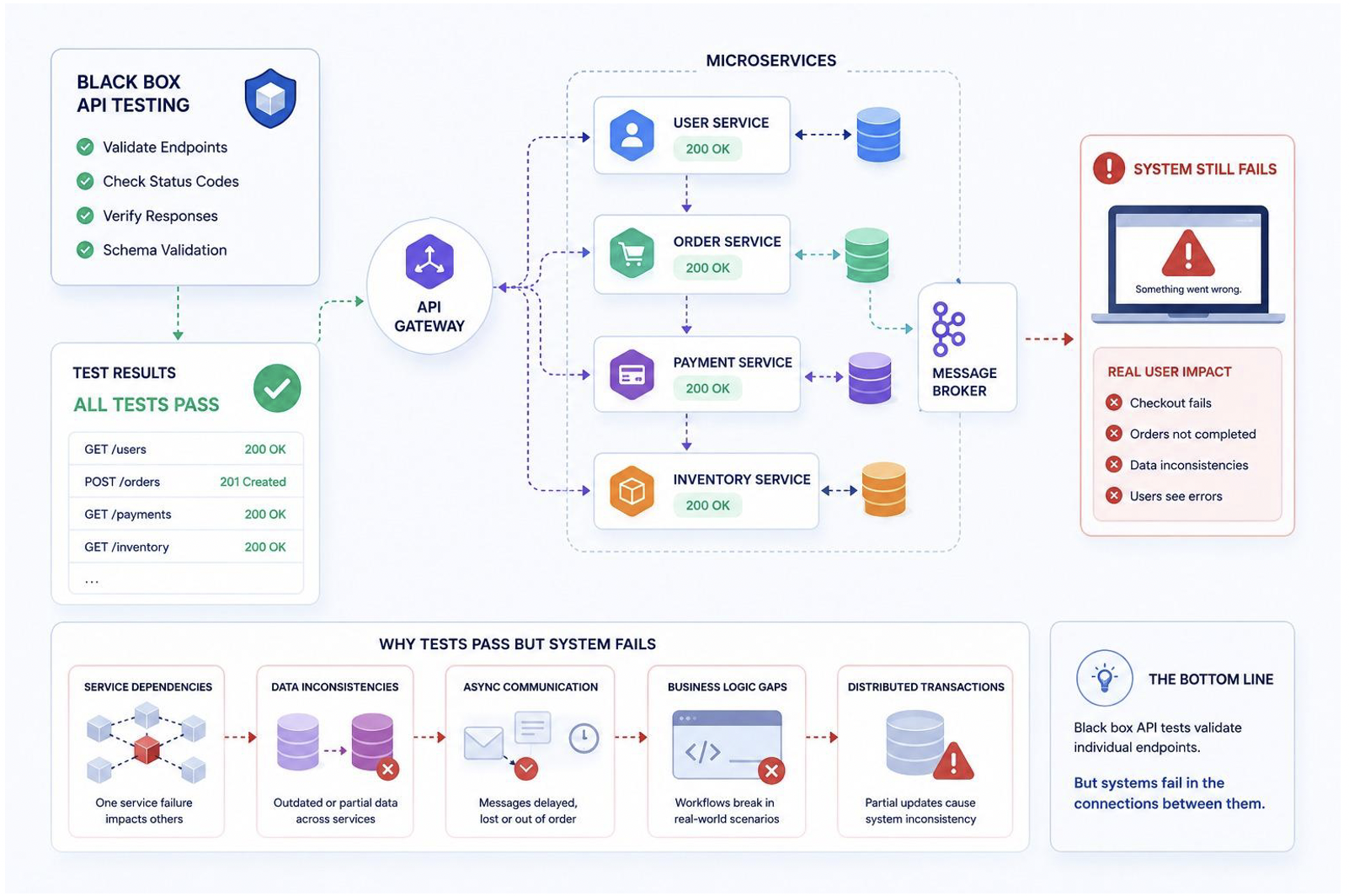
The CI pipeline is green. Every API test passed. The team ships to production, and within forty minutes, incident alerts start firing. A downstream payment service is returning unexpected null values on a specific transaction flow. The API test for that exact endpoint passed clean. It has been passing clean for two months.

This is not a hypothetical. It is the specific failure mode that microservices architectures introduce when black box testing is applied in the same way it was applied to monolithic systems. The test methodology is sound. The execution is the problem.
Understanding why requires a close look at what black box testing actually means in a distributed system, where the assumptions that make it effective in traditional environments collapse under the weight of service interdependency.
What Black Box Testing Means in a Microservices Context
Black box testing, at its core, tests a system from the outside. The tester interacts with the exposed interface, provides inputs, observes outputs, and validates behavior against expected results. No knowledge of internal code structure is required. This is the opposite of white box testing, which examines internal logic, code paths, and implementation details directly.
The distinction between black box and white box testing becomes significantly more complex in microservices architectures. A microservice has two kinds of external surfaces. The first is its own API, which is what traditional black box testing targets. The second is its behavior when connected to the other services it depends on: databases, message queues, third-party APIs, and sibling services in the same cluster.
Most black box testing strategies cover the first surface thoroughly and ignore the second almost entirely. That is where production failures are waiting.
When a team writes black box tests for a microservice, they typically test the service’s API in isolation. The service gets a request, it returns a response, the test validates that response. What the test does not validate is how that service behaves when the payment processor it depends on returns an unexpected schema, when the inventory service responds with a timeout instead of an empty array, or when the user data service returns a field that changed shape after a silent contract update three weeks ago.
Why Tests Pass in Isolation
The reason tests pass when systems fail in production is not a testing tool problem. It is a dependency modeling problem.
To run black box tests without standing up every downstream dependency in a live state, teams use mocks. A mock is a stand-in for a real dependency. It intercepts calls to the downstream service and returns a predetermined response. The test validates that the service under test handles that response correctly.
Mocks are useful, but they introduce a critical vulnerability: they represent what the developer believed the downstream service would return at the moment the mock was written. They do not represent what the downstream service actually returns today.
In a microservices architecture deployed on Kubernetes, downstream services evolve independently. A contract that was accurate six months ago may have shifted. An additional field may have been added to a response schema. A previously optional field may now be null under certain conditions. A latency profile that was reliably under 200 milliseconds may have degraded as data volumes grew.
The mocks know none of this. They keep returning the response that was accurate when they were written. The tests keep passing against those mocks. The system keeps drifting away from the behavior the tests are actually validating.
This is mock drift. It is the defining quality problem in cloud-native black box testing, and it compounds silently with every independent service deployment.
The Environment Gap
Beyond mock drift, there is a second failure mode that is structural to how cloud-native systems operate: the environment gap between where tests run and where production runs.
A black box test executed in a CI pipeline runs against a containerized test environment. That environment has specific network policies, resource limits, service mesh configurations, and infrastructure behaviors. Production has different versions of each of those things. The difference is often small. The impact of that difference on specific code paths can be significant.
Kubernetes resource limits in a test environment are frequently more generous than in production, because the test environment does not share infrastructure with real traffic. A service that behaves correctly under relaxed resource constraints may behave differently when CPU throttling kicks in on a high-traffic production cluster. A service that connects cleanly to dependencies in a controlled test environment may experience connection pool exhaustion under real concurrent load.
The black box test cannot see any of this. It is testing from the outside, which is its strength. But when the outside is not representative of production, the test’s external validation has limited predictive value.
How Microservices Architecture Magnifies Both Problems
These problems exist in monolithic systems too, but microservices architecture makes both significantly worse.
In a monolith, a single deployment contains most of the behavior the system needs. Black box testing the monolith means testing a large proportion of the system’s real behavior in a single interaction. The number of external dependencies is smaller, the service surface is unified, and the opportunity for mock drift is limited.
In a microservices architecture with forty services, each service has its own deployment cycle, its own API contract, and its own capacity to change independently of the services that depend on it. The number of potential contract violations grows with every service boundary. Each boundary is an opportunity for a mock to fall out of sync with reality.
The problem is not that teams are testing incorrectly. The problem is that the testing strategy was designed for a world where the system was one thing, and it is being applied to a world where the system is forty things communicating with each other through network calls.
The Difference Between Black Box Testing and Black Box Thinking
There is an important distinction between the mechanics of black box testing and the philosophy behind it.
The philosophy of black box testing is sound, and it applies directly to microservices. Test what the system does, not how it does it. Validate observable behavior, not internal implementation. Treat each service as a unit of behavior with defined inputs and expected outputs.
That philosophy becomes a problem when teams conflate “black box” with “isolated.” A microservice is not actually a self-contained system. It is a node in a graph of dependencies. Testing it in isolation, against mocked dependencies, produces results that reflect how the service behaves in an artificial environment rather than how it behaves when connected to the real graph.
Genuine black box testing in a microservices context should test the service through its API, as the philosophy requires, but with dependencies that reflect real production behavior rather than developer assumptions.
The comparison with white box testing is instructive here. White box testing examines internal code paths that black box testing deliberately ignores. What black box testing should not ignore is the external environment in which the service operates. The service’s internal code is a black box. Its dependency behavior is not.
What Good Black Box Testing Looks Like in Cloud-Native Systems
Addressing mock drift and the environment gap requires changing how test inputs and dependency responses are sourced.
The most reliable source of dependency behavior is production traffic itself. When real requests flow through a service in production, the upstream requests, the downstream calls, and the responses from every dependency are all captured in their actual, current form. Those captured interactions reflect the real contracts between services as they exist today, not as they were documented six months ago.
When tests are generated from captured production traffic rather than from developer assumptions, the mock drift problem largely disappears. The mocks are not imagined responses. They are recordings of what the dependencies actually returned when real users made real requests. If the payment service started returning a new field three weeks ago, that field appears in captured mocks automatically. No developer has to notice the change and update the mock by hand.
This approach represents black box testing in its most honest form. The service is still being tested from the outside, through its API, without knowledge of its internal implementation. But the external environment the service is tested against reflects production reality rather than a frozen snapshot of what that reality looked like at some point in the past.
Replaying captured production traffic as test cases also addresses the environment gap in a meaningful way. Production traffic is not synthetic. It reflects the real distribution of inputs that real users send, including the edge cases and boundary conditions that rarely appear in developer-authored tests. A test suite derived from production traffic covers the scenarios that actually happen, not the scenarios that a developer anticipated when writing the test.
The Operational Reality
Implementing traffic-based black box testing in a cloud-native environment requires solving a specific infrastructure challenge: capturing traffic at the network layer without modifying application code.
In a Kubernetes environment, this can be accomplished through eBPF-based traffic capture, which intercepts network calls at the kernel level without requiring SDK integration or code changes. The service runs normally, the traffic capture operates transparently, and the captured interactions are stored as reproducible test cases and dependency mocks.
This approach works across language runtimes and frameworks because it operates below the application layer. A polyglot microservices architecture, which is the norm rather than the exception in cloud-native systems, can be covered by the same capture mechanism regardless of whether services are written in Go, Python, Java, or Node.
The resulting test suite runs in CI against recorded mocks, produces deterministic results, and validates service behavior against real production interaction patterns. When a downstream service changes its response schema, the next round of traffic capture reflects the change and the test suite updates accordingly.
The Persistent Value of White Box Testing
Addressing the limitations of black box testing in microservices is not an argument against white box testing. The two approaches answer different questions.
White box testing validates that specific code paths execute correctly. It catches logic errors, branch coverage gaps, and implementation mistakes that external testing cannot see. For complex business logic, edge case handling, and security-sensitive code, white box testing is irreplaceable.
The argument is not that black box testing should replace white box testing or vice versa. It is that black box testing in microservices needs to be grounded in real service behavior to deliver its actual promise. A test that validates observable external behavior against a mock that was accurate a year ago is not black box testing. It is archaeology.
Why the Green Pipeline Is Not Enough
The teams that discover the limits of their current black box testing strategy usually discover them through a production incident. The discovery is expensive: debugging time, user impact, rollback coordination, and post-mortem effort that consumes days of engineering capacity.
The alternative is to close the loop between what tests validate and what production actually does before the incident happens. In a cloud-native architecture where services deploy independently, and contracts evolve without synchronized coordination, that loop does not close itself. It requires deliberate infrastructure investment in how tests are generated and how dependency behavior is kept current.
A green CI pipeline built on stale mocks is not evidence that the system works. It is evidence that the system works in the conditions that existed when the mocks were written. For a microservices architecture running in production, those conditions are a moving target.
The teams that understand this distinction build testing infrastructure that moves with it. The teams that do not will keep seeing production incidents that their green pipelines did not predict.
Final Thoughts
Black box testing remains one of the most reliable approaches to validating software behavior from the outside. The methodology is not broken. What breaks in cloud-native systems is the assumption that a passing test suite reflects production reality. Microservices architectures demand a more honest version of black box testing—one where the external environment being tested against is sourced from real traffic, not developer assumptions.
When mock drift is eliminated, and test inputs reflect actual production behavior, the gap between a green pipeline and a reliable system closes considerably. The green pipeline is worth trusting again once the mocks it runs against are worth trusting first.
