
Trilio Expands Kubernetes Protection Reach
Trilio during the KubeCon + CloudNativeCon North America 2020 virtual conference announced it has updated its agentless data protection software to make it easier to back up and recover multiple Kubernetes clusters residing in cloud computing environments.
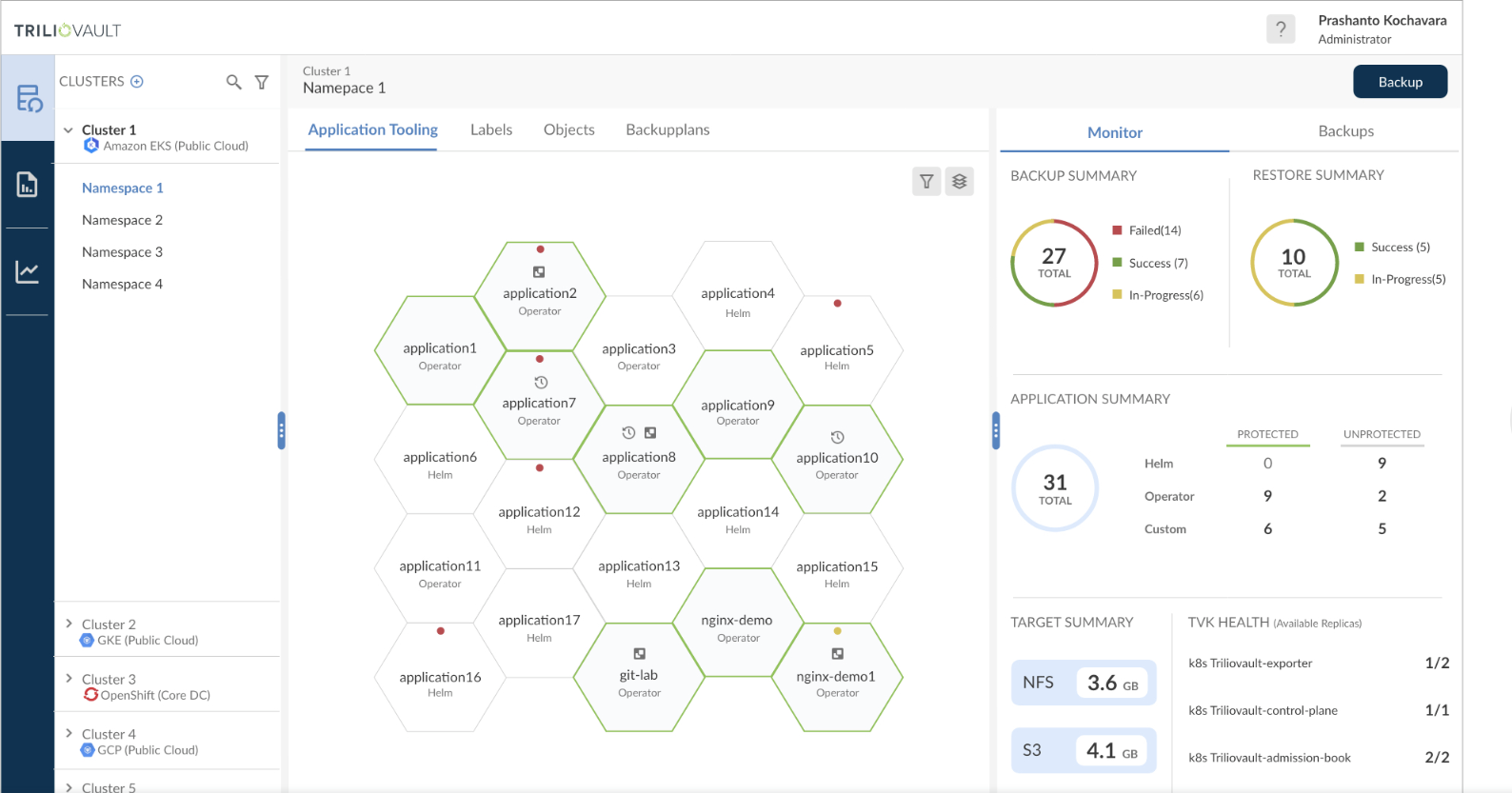
Company CEO David Safaii says via a revamped management console, version 2.0 of TrilioVault for Kubernetes can now protect Kubernetes clusters deployed both on-premises as well as in emerging hybrid cloud computing environments.

At the same time, Trilio has added support for the namespace capability of a Kubernetes cluster, which makes it possible to unify the backup of all applications and data that share a namespace. IT teams can also now more easily search and view backup targets without being connected to a cluster. It’s also now possible to adjust restore plans or adjust the application behavior at a granular level before the application is restored.
The company has also added support for Helm sub-charts and certified compatibility with Rancher Server with Rancher Kubernetes Engine (RKE) along with databases such as Cassandra, MongoDB and MySQL.
Trilio has been making the case for an application programming interface (API)-centric approach to backup and recovery within Kubernetes environments. Data protection is becoming a more pressing issue in Kubernetes environments as the number of stateful applications deployed on the platform steadily increases.
Given the fact that applications running on Kubernetes clusters are usually based on microservices, IT organizations are also now more sensitive to recovery times. A well-constructed microservices application might not fail entirely, but there is certainly going to be a lot of pressure to make certain applications can be fully restored to its optimal level of performance as quickly as possible.
Less clear right now is who on the IT team will manage backup and recovery. As more responsibility for managing IT continues to shift left toward developers, the responsibility for backup and recovery in many cases is moving toward DevOps teams that want to employ APIs to automate as much of the process as possible. In other cases, administrators that would employ the Trilio management console are emerging to manage Kubernetes operations, including backup and recovery.
Those administrators are also taking advantage of the Trilio management console to migrate data into and out of cloud computing environments as circumstances dictate, Safaii says. As such, data protection tools are now also being evaluated based on their ability to both protect and manage data. In fact, he notes, there may be use cases where even developers may prefer to access a console to manage a one-time task.
Regardless of who is responsible for managing the process, application owners expect data residing on a Kubernetes cluster to be recoverable quickly from any point in time. As such, data protection tools in Kubernetes environments are being evaluated more stringently on recovery times. The challenge IT teams face now is the amount of data on Kubernetes clusters that needs to be backed up and recovered is steadily increasing.
