
5 to 1: An Overview of Apache Cassandra Kubernetes Operators
Apache Cassandra is one of the best-kept open secrets in “web-scale” enterprise-grade technology platforms. The distributed open source database started at Facebook to solve its inbox search problem, taking the best ideas from the Google BigTable and Amazon Dynamo papers to create a highly available and scalable NoSQL database. Now on the eve of its 4.0 release, Cassandra is in a category of its own and leads a class of databases with an easy-to-use CQL query language syntax similar to SQL, familiar to most developers.
Organizations that use Cassandra need high availability and fault tolerance, at high speeds, around the world—and have realized (through use or research) that the other potential datastores fall short. Cassandra’s feature list is long but here’s what makes it unique:

- Open source Apache Software Foundation project.
- Built for fast writes and fast reads.
- Masterless/peer-to-peer architecture. No single point of failure.
- Globa/regional replication across data centers.
- Familiar CQL DDL/DML language (a similar subset of SQL).
- Ability to host across public cloud, hybrid and multi-cloud on bare-metal, VMs or containers.
- Infinitely and linearly scalable with additional hardware.
- Drivers for Java, Scala, Go, Python, Node and .NET
- Proven at scale by Apple, Netflix, Spotify, CapitalOne, McDonalds and thousands more.
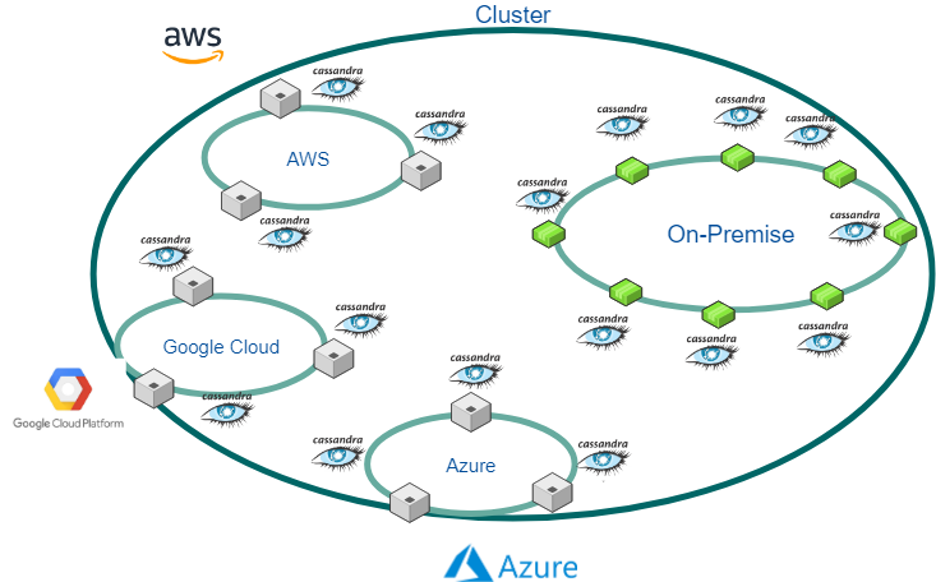
Cassandra is responsible for storing and moving the data across multiple data centers, making it both a storage and transport engine. If you want to share data with another part of the enterprise, you can do this by creating a data center and changing the properties of a keyspace to replicate to that data center.
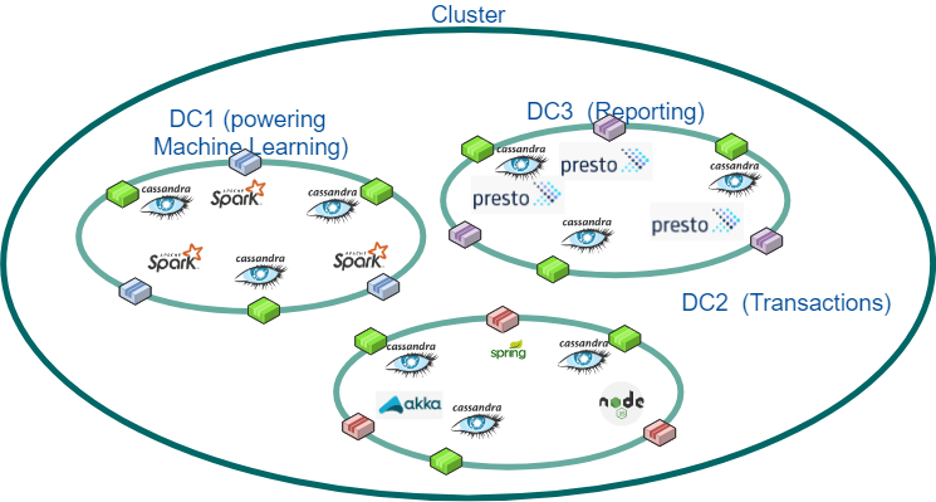
Figure 2 is an example of the power of Cassandra combined with other technologies. The masterless replication across data centers allow for translytical architectures in which the same data set can power a transactional workload from an API as well as an analytical workload from Apache Spark, while having another workload to stream data in with Apache Flink or provide reporting capabilities using Presto.
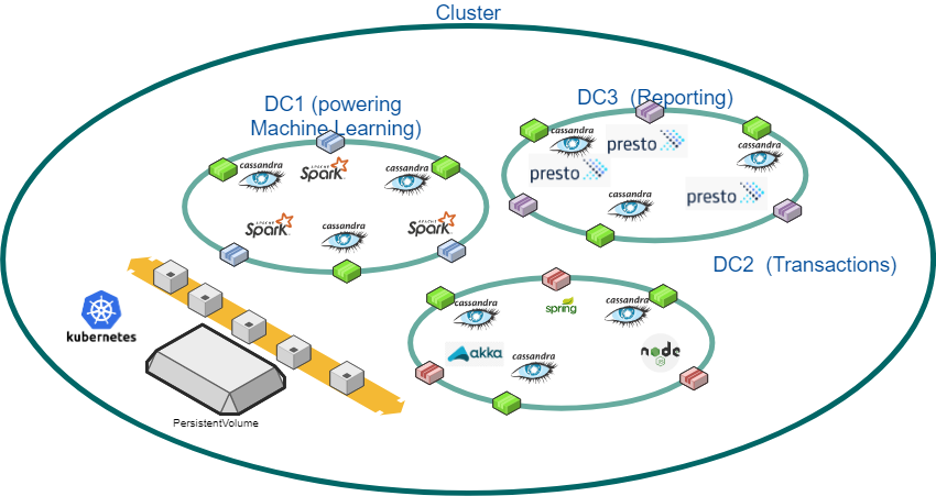
Together with Docker, Kubernetes has democratized so many aspects of what IaaS providers have to offer but the hardest layer has always been data. Kubernetes is a technology that can match well with Cassandra’s capabilities because it shares the features of being linearly scalable, vendor-neutral and cloud-agnostic. Since Cassandra can scale linearly, operators can add or remove hardware resources to account for changes in load or data. This makes Kubernetes an amazing orchestration platform for Cassandra and any other technologies.
There is a healthy debate in the Cassandra community about whether it belongs in Kubernetes—and whether databases belong in Kubernetes at all—because other orchestration tools are good enough, though the growing user base of Kubernetes in hobby and commercial realms suggests that we need to provide an operator that can keep up with the demand.
Kubernetes and Cassandra share a lot in common because they were both created for scale and to run on any cloud:
- Both Kubernetes and Cassandra are open source. This means that users and operators only pay for it if they need support or services.
- Both can run across public cloud, on-premises, hybrid cloud, and multi-cloud on bare metal and VMs. This gives users and operators the freedom to use any cloud without any vendor lock-in.
- Kubernetes scales operations for Apache Spark, Apache Kafka, Apache Flink, Akka, and Presto―and all work really well with Cassandra.
- Kubernetes scales containerized Java, Scala, Go, Python, Node and .NET applications, which also work well with Cassandra.
Because both are open source, platform architects can design solutions that future-proof their architecture across any infrastructure, whether in development locally or in production across clouds.
While it’s possible to run Cassandra on Kubernetes without an operator, it is by far the better option. Five organizations have developed operators to make it easier to run containerized Cassandra on Kubernetes. Recently, these organizations came together to form a special interest group (SIG) to set goals for what the operator should do at different levels to find a path for creating a standard community-based operator. The Operator Framework suggests five maturity levels for operator capabilities starting from basic installation to auto-pilot.
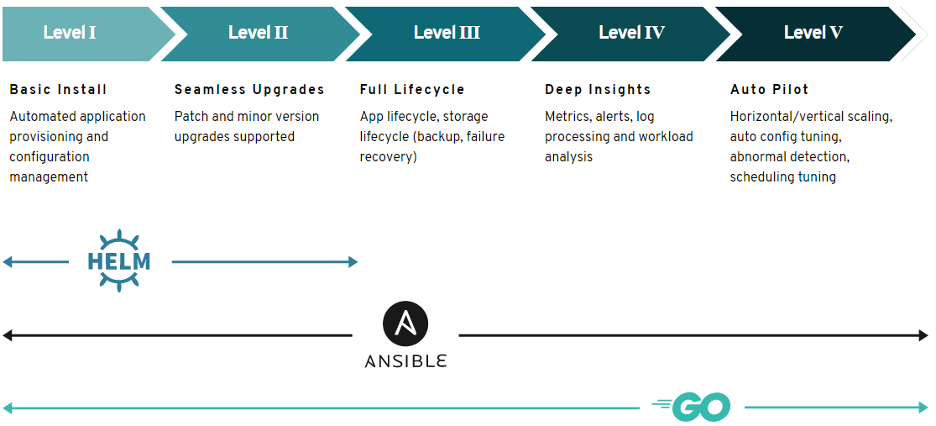
The five Cassandra Kubernetes operators all come from different backgrounds and all have great features. To collaborate, the first goal is to develop requirements for the operator for each level. The task for this goal is to create a canonical Custom Resource Definition (CRD) that will set the syntax/schema that will be used to create Cassandra clusters on Kubernetes. Once this is done, an operator can be created to use the CRDs in an intelligent manner.
Luckily, we’re not starting from scratch, because the pioneers of Cassandra on Kubernetes from the different projects are all collaborating. Hopefully much of the prior work can be leveraged in the combined effort. The major operators out publicly today are those by Sky UK, Orange Telecom, Instaclustr, Elassandra and DataStax (list sourced from the awesome-cassandra project):
- Cassandra Operator – A Kubernetes operator by SkyUK that manages Cassandra clusters inside Kubernetes. Well-designed and -organized. This was among the first operators to be released.
- Cassandra operator – The Cassandra operator by Instaclustr manages Cassandra clusters deployed to Kubernetes and automates tasks related to operating a Cassandra cluster.
- CassKop – This Kubernetes operator by Orange automates Cassandra operations such as deploying a new rack-aware cluster, adding/removing nodes, configuring the C and JVM parameters, upgrading JVM and C versions. Written in Go. This one was also one of the first ones out and is the only one that can support multiple Kubernetes clusters using Multi-CassKop.
- Cass Operator – DataStax’s Kubernetes Operator supports Apache Cassandra as well as DSE containers on Kubernetes. Cassandra configuration is managed directly in the CRD, and Cassandra nodes are managed via a RESTful management API.
- Elassandra Operator – The Elassandra Kubernetes Operator automates the deployment and management of Elassandra clusters deployed in multiple Kubernetes clusters.
As with any Kubernetes operator, the goal is to create a robot that makes easier the manual work of setting up, maintaining and scaling complex configurations of containers in Kubernetes. The different operator maturity levels mentioned above offer a road map to creating a robust operator for Cassandra users that is easy to use.
Most likely if someone is thinking about moving Cassandra workloads from public cloud, on-premises VMs, or even on-premises bare metal servers to either a public or private cloud hosted Kubernetes, they’ll want to evaluate whether the existing architecture could run and be performant.
As part of the SIG, we’re also coming up with reference architectures on which to test the operator. Here are some of the common and most basic reference architectures that are likely candidates. If you’re a current or prospective end user of Cassandra and Kubernetes and have opinions on what you’d like to see, the community is requesting feedback via a survey (closes Sept. 17).
