
Why Backup Won’t Work for Stateful Containers
This article is part of a series of articles from sponsors of KubeCon + CloudNativeCon 2020 North America
Containers are stateless, right? That’s what we keep hearing repeatedly, anyway. In this blog, we will debunk some of the myths and misconceptions, and work through why backup solutions won’t work for stateful containers.

Containers are Stateless
Let’s begin with the most obvious myth: containers are stateless. Technically, this is not true. A container can contain state, but that state is ephemeral, unique to that container and local to the host it’s running on. The myth comes from the fact that container images are stateless and persistent data should be stored outside of the container image. Let’s dive in.
As we discussed in our blog, “Stateful vs. Stateless,” container images are a layer cake of read-only layers. Each layer contains changes from a configuration file with installation and configuration commands. After the commands from the config file are run, the resultant file system changes are captured into a disk layer.
When running a container, a temporary writable layer is added on top of the disk image. This writable layer is specific and unique to that specific container on that specific host and survives any container restarts. But this writable layer is not meant to contain any stateful data, like persistent application data. It is only used as a temporary space for running the application in the container.
Where Do Containers Store State?
So, we now know that containers can’t store their state in the container image. Instead, state is stored in external persistent storage, such as object, block, or file storage systems and services.
In enterprises, this storage can come from any number of sources, but it’s most likely to live on an enterprise storage array, delivered into the Kubernetes environment via persistent volume claims (PVCs). From a storage admin’s perspective, there is not a lot of difference between storing persistent data from a VM or from a container: it’s an application accessing data that is stored on some known, managed piece of storage.
Where Backup Solutions Fall Short
And this is where we start to see how backups for stateful containers will fall short. On the one hand, the traditional array-based solutions with snapshots fall short just like they did for virtual machines: Storage-based snapshots are not adequate for backup or data mobility. They’re periodic, require scheduling, and don’t deliver the granularity demanded by DevOps teams today. In a dynamic, fast-paced world where containers are regularly starting up and terminating as needed, a backup snapshot from last night might as well be eons old.
Additionally, backing up at the storage layer almost always means vendor lock-in. As your business evolves, being stuck with a single storage solution, chosen years ago, does not enable the agility needed for today’s resilient IT teams.
Secondly, containers are not the right entry point to backing up data either, for two reasons:
Containers are massively scalable with many identical instances each doing a small part of the same job; no one single container is ‘the master’ for an application. There may be multiple (two to hundreds or thousands) containers accessing the same persistent data at any given time. This is very different compared to virtual machines, wherein the vast majority, only a single VM is accessing the same data.
Containers are ephemeral and not guaranteed to be running when backups need to be created. This is different from VMs, which are expected to be running and are kept running smoothly by using mechanisms like VMware HA. Container application availability and resilience is not determined by any single container.
The architectural differences of containers show why backup solutions won’t work for containers, and we need a different way of doing continuous, granular backups of stateful application data. Bolting on dated backup technology, often 20-30 years old at this point, will not let companies keep pace with the demands of modern IT and next-gen technologies such as containers and Kubernetes.
Finding the Right Solution
The right solution does not rely on the container for backup and replication purposes, nor is it reliant on any one storage solution. Instead, it installs on a Kubernetes cluster as a stateful DaemonSet and provides continuous data protection with an RPO as low as 5 or 10 seconds.
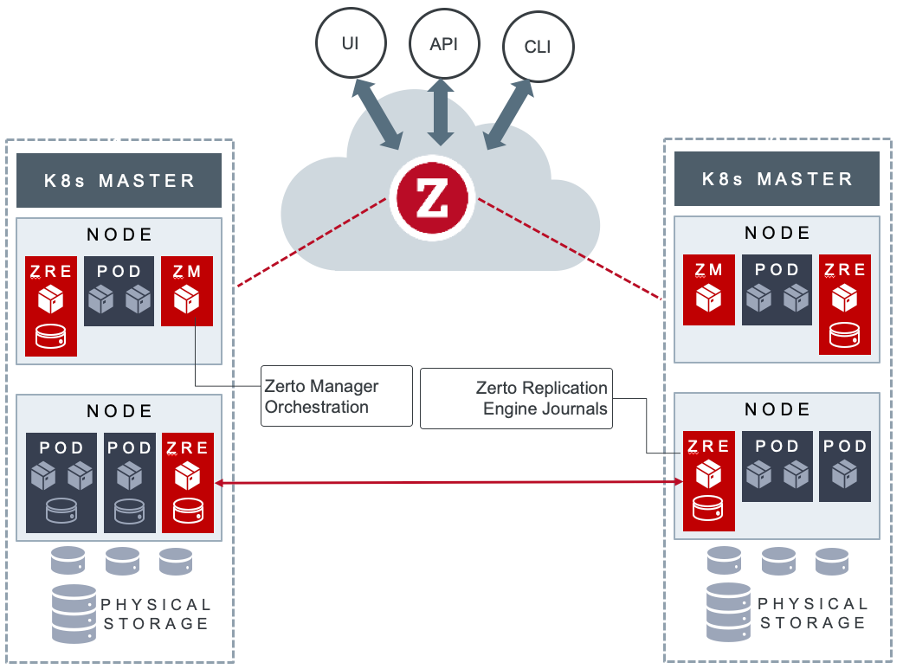
These DaemonSets ‘tap’ into the persistent storage transparently to get access to the persistent data without being dependent on any one container. By coordinating across all worker nodes in the cluster and the cluster API itself, Zerto for Kubernetes can work out the most efficient way of journaling the persistent data without duplication or container performance impact.
It can also be linked across clusters, replicating persistent data for disaster recovery purposes. It’s completely storage-agnostic, and supports any CSI-compatible block storage, which makes it ideal for data mobility and migration purposes.
Make sure the solution you choose does not capture just that stateful data, but it also captures the Kubernetes state for each application, offering data protection for components such as ConfigMaps and Services to be able to re-create the application on the same or another cluster for data recovery purposes.
Visit the Zerto for Kubernetes web site for more information and to join the community discussion.
