
D2iQ Eases Kubernetes ML Workload Deployment
D2iQ has made generally available a suite of open source software components that make it simpler to deploy machine learning workloads on Kubernetes clusters.
Tobi Knaup, D2iQ CEO, says D2iQ Kaptain is based on an opinionated implementation of a subset of Kubeflow, an open source machine learning toolkit for Kubernetes that traces its lineage back to Google’s deployment of the TensorFlow framework for building artificial intelligence (AI) models using a pipeline dubbed TensorFlow Extended.

D2iQ has combined its instance of Kubeflow with the D2iQ Konvoy distribution of Kubernetes, along with the elements of the open source Apache Spark in-memory computing framework and Horovod, an open source framework for training AI models based on deep learning algorithms.
The goal is to make it possible for a data science team to deploy frameworks for building AI models using Operators and familiar Jupyter notebook tools, provided by D2iQ, that eliminate the need to know how to operate the underlying Kubernetes cluster, Knaup says.
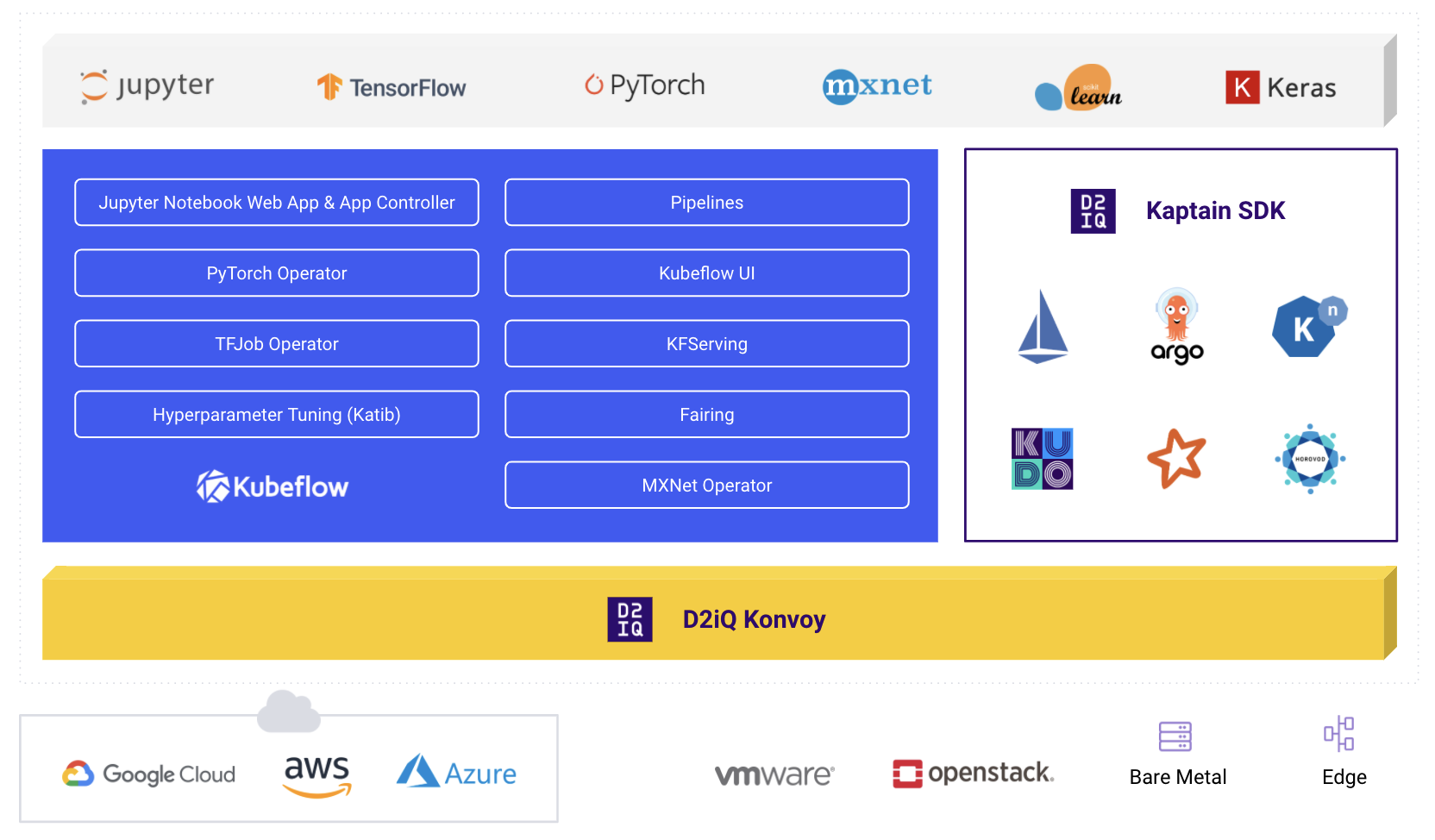
Given the amount of data required to train an AI model, data scientists need a platform that can easily scale up and down as required. As such, there is a high correlation between organizations that are building AI models and adoption of Kubernetes. D2iQ Kaptain is designed to break down operational barriers that, today, make it challenging for data scientists that lack DevOps skills to deploy an AI model in a production environment, Knaup says.
Those data science teams can also tap D2iQ for support on-demand, as required, versus having to rely on an internal IT team that may lack Kubernetes expertise, Knaup says.
Moving AI models into production environments is a major challenge. Organizations today are adopting machine learning operations (MLOps) best practices that borrow heavily from concepts originally defined by DevOps practitioners to automate as much of the AI model development and deployment process as possible. However, building an AI model is a painstaking effort. Most data science teams today are fortunate if they are able to deploy a handful of AI models a year. The inference engines those AI models enable are often embedded within applications that are updated multiple times a month by DevOps teams. Organizations that embrace MLOps and DevOps will need to find a way to bridge that divide.
That issue is becoming more acute, because once an AI model is deployed, it needs to be continuously updated as new data sources become available. It’s also not uncommon for AI models to be replaced once it becomes apparent that the assumptions used to train the AI model have become obsolete as business conditions change and evolve.
Not surprisingly, many AI initiatives fail outright, for one reason or another. Nevertheless, it’s only a matter of time before most applications are infused, to one degree or another, with AI capabilities. The operational challenge most early adopters of AI are wrestling with is, first, making sure the data used to train the AI model is reliable and, second, that those AI models can scale. That latter issue not only pertains to when the AI model is trained, but also the inference engine that gets deployed in a production environment.
It may be a while before MLOps and DevOps practices meld, but the one thing that is clear – that journey will most often begin with the deployment of a Kubernetes cluster.
