
Where is Your Data?
I’ve written a series of articles on cloud-native data architecture, including creating your cloud-native data strategy, getting your data architecture right in cloud-native applications and five rules for getting data architecture right. In these articles, I’ve talked about how to create and adjust your data architecture to work effectively in a cloud-native application.
But there is another topic important to cloud-native data architecture, and that is data geography. Where should you locate your data, and how does the location impact your customers and their expectations?

Geography is Important
Where are your customers located? When you determine your data architecture, it’s important to understand where your customers are located and what expectations they have for accessing your data.
Often, applications use a very simple approach to the geography question—they ignore it. They create a single instance of their application and its data in a single region and make that region accessible worldwide. This is illustrated in Figure 1.

This approach provides a great customer experience for those in the region where the application is located (such as North America in this figure), and a degraded experience in other regions, due to internet latency across regions. This approach is common with many SaaS companies.
For other companies, this same approach is replicated in each region of interest. Multiple independent regional instances are created, as shown in Figure 2.
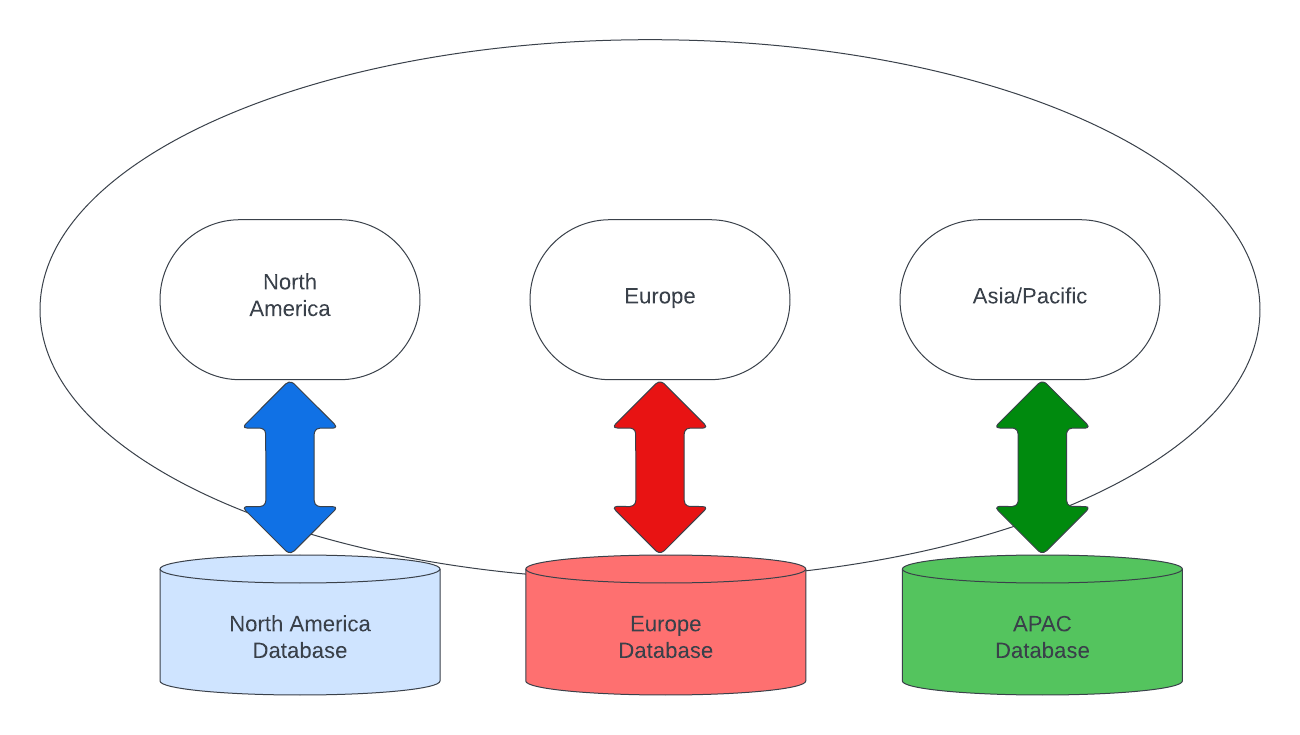
This approach solves the performance expectations for each region since each region has a localized version of the application. However, customers that want or need to share data across regions can’t easily do it since each application instance is unique and separate.
If global universal data is important for your application, the data can be synced across regions. In this case, a single dataset is used worldwide, yet it is accessible locally via a regional copy of that data. This is illustrated in Figure 3.
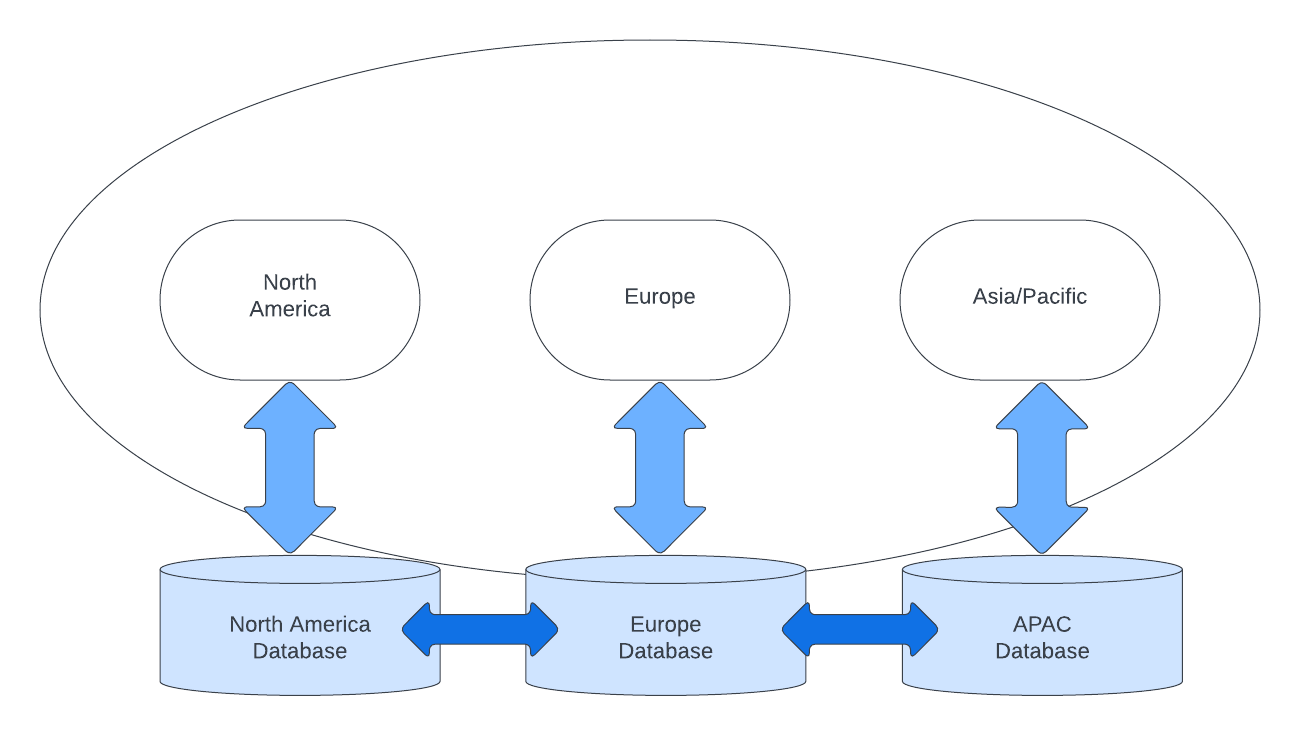
Data is automatically synchronized across regions in order to keep all regional copies using the same dataset. While this solution seemingly solves the regional data latency problem, it actually introduces a related problem—data synchronization lag. It takes time to synchronize data, so data that is actively being updated can get out of sync between regions. A change to one piece of data in two different regions can unknowingly cause a collision and create data integrity issues.
Geopolitical Influence
Complicating all of this is the effect of regional laws and regulations that specify data storage requirements in some regions and industry-specific requirements that may limit data availability in other regions.
Laws such as Europe’s GDPR and California’s CCPA impact how data is stored and used in different geographic locations. Both laws restrict how users’ personal data is shared and consumed across regions. Additionally, various security laws and regulations may impact which countries are allowed to access different types of data. For instance, some information on encryption policies often can’t be shared with some countries. Additionally, actively storing data in some regions may be regulated for some types of data. Tax nexus and other legal and financial concerns can also impact where data can and cannot be stored.
These laws and regulations can impact your global cloud-native data architecture significantly. In many cases, a hybrid approach to data geographic architecture may be needed, allowing some data to be shared globally and other data to remain regionalized. Such an architecture is illustrated in Figure 4.

Here, data that is global in nature is synchronized across regions, while data that is region-specific or region-restricted is stored in a regional database that is not shared. The application makes use of this hybrid data architecture to present a complete experience in any given region yet provide some data sharing at a global level.
Determining Your Data Architecture
Is it important that your data be available globally, or is a regionalized version required? Do you have regional restrictions on what data you can store and who can access it?
If you can share data across regions, how tightly synchronized must the data be? Can your application handle a bit of skew at a global level with rapidly changing data?
The answers to these questions will dictate whether you provide a global, regional or hybrid data architecture. Determining where that data can and cannot be stored and when and how to synchronize it between regions is a central aspect of designing a cloud-native data architecture plan for your globally enabled application.
The cost of mistakes is high too. Making a poor architectural geography decision can cause issues with scaling, availability and even legal conformance. Changing your data architecture after your application has matured is not easy. It’s far easier to address your key data requirements as early in your architectural process as possible.
