
Open Source Tooling to Run Large Language Models Without GPUs Locally
Large language models have taken the world by storm, with many companies already integrating them or actively exploring their potential. And the typical starting point for these explorations is to build prototypes. However, prototyping with LLMs isn’t always cheap. The inference cost, which is calculated on the basis of token usage, can vary significantly depending on the type of application being built.
Furthermore, given the breadth of models now available, it would be unfair to limit ourselves to just the popular ones like GPT, Claude or LLaMA. Just as different frameworks are designed to solve specific problems, a wide variety of models have emerged to support a number of distinct use cases. The prototyping phase is the ideal time to explore this diversity and identify the most suitable option for your needs.

And the best way to prototype is to start by running the models locally. In this article, we will explore the various options available for running models locally, along with the trade-offs involved. We will also provide recommendations on when a particular approach may be more suitable than others, depending on the scenario and requirements.
llama.cpp
The first popular method to run LLMs on the Desktop came with the release of llama.cpp. It is based on Meta’s LLAMA models and allows execution on Windows, Linux and macOS without the need for GPUs, thanks mainly to its quantisation optimisation technique.
While there are multiple ways to run llama.cpp locally, the most common strategy is to start it up as an HTTP server and interact with it using API’s. For instance, if you are using Windows, typical commands involve:
Step 1: Install the llama.cpp using the winget command.
“` winget install llama.cpp“`
Step 2: Use the llama-server command with the hf flag to download a model from the Hugging Face repository and run it.
“`llama-server -hf MaziyarPanahi/Llama-3.2-1B-Instruct-GGUF“`
Step 3: Running step 2 opens up a GUI on localhost:8080, which can be used for chat. The chat completion api /v1/chat/completions, which is OpenAI API compliant, is also available on the same port. The chat completion endpoint can be used directly if one does not want to use the UI.
We barely scratched the surface with llama.cpp. For example, there are more rudimentary ways to run the cpp using commands like llama-server and llama-run.
The biggest advantage one can get with llama.cpp is the customisation. For example,
- You are able to pick the quantisation formats for your models, whether it is int8 or float16.
- Choose the context window size for your prompt.
- Enable flags for avoiding memory locking.
- And configure the number of CPU threads to use.
Coming to the complexity, llama.cpp only supports files with GGUF (GPT-Generated Unified Format). As a result, you must either download a model in this format or convert the model file into the required format. This is something the users have to do manually by using the conversion scripts that Llama provides in their repository. The hugging face repository for gguf also provides some models that are already in this format. For example, the MaziyarPanahi/Llama-3.2-1B-Instruct-GGUF we discussed earlier is an example of a model already available for us in GGUF format.
So, in summary, if you want to have every tiny bit of control from how the model is quantised to how it is loaded into memory, llama.cpp is the perfect tool.
Ollama
Ollama can be thought of as the LLM Runtime + Model Manager + REST API, all packaged into a single executable. Similar to Llama Cpp, it is available for Windows, macOS and Linux. All one needs to do is download the executable, if you are using Windows, for example, install it and run the ‘ollama run’ command.
Step 1: Download Ollama from here.

Step 2: On the command line, enter run with the model of your choice from the list. ollama run gemma3.
Another option is to expose a rest api using Ollama Serve.
The major advantage of Ollama is its ease of use. Though it is built out of the llama. In C++ architecture, it hides all the complexity of GGUF formatting, quantisation, and tuning flags.
However, we are restricted to the list of models Ollama provides. For any latest model, one has to wait until it becomes available in their repository.
More precisely, Ollama is the best tool if one needs to get running with LLMs immediately without having the need to understand the intricacies.
Docker Model Runner
Docker Model Runner is the newest addition to the list of tools that can run models locally. Made available in April 2025, the runner packages the inference engine into Docker Desktop, using which the model is served. It also comes with GPU acceleration when running on Apple silicon-powered chips. In simple terms, GPU acceleration is one way to achieve faster inference when running on local hardware.
In order to use the runner:
- Download Docker Desktop.
- Issue the “`docker model pull ai/smollm3“` command to download smollm3 model locally.
- Use the “`docker model run ai/smollm3“` to run the model.
While the command line is one way, another strategy is to use the UI that docker provides. For example, the below screenshot shows how you could potentially talk to the LLM model using the Docker Desktop web interface.
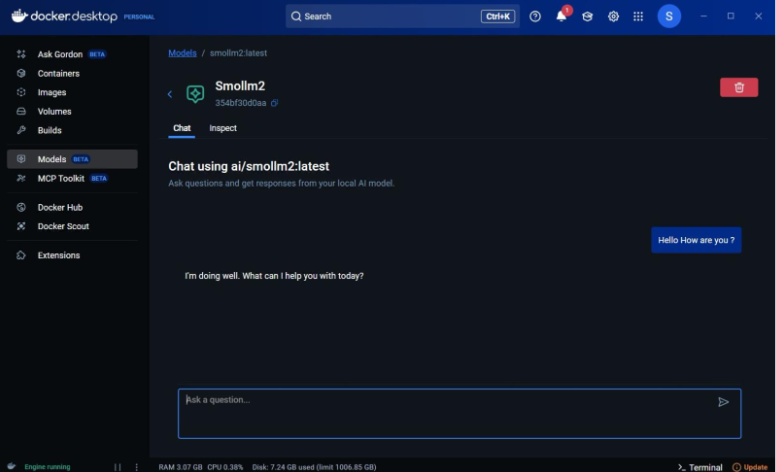
The list of models available for download can be found in the Docker AI repository.
One of Docker’s major advantages is its widespread adoption within the cloud and container ecosystem. By packaging models as OCI (Open Container Initiative) artefacts and integrating them into container registries, developers can download and run models using familiar workflows, just like how they do with traditional containers.
Docker is also adding support to run the runner in a Kubernetes Cluster. And because Kubernetes is the de facto way of running containers in the cloud, it will make running models in production easier.
