
How SREs are Using AI to Transform Incident Response in the Real World
In today’s complex, fast-scaling cloud environments, traditional incident response mechanisms are insufficient. Manual triage, constant alert storms and siloed monitoring systems strain SRE teams, delaying remediation. This article introduces a new approach: An AI-augmented incident response model that fits with modern SRE practices. It outlines a five-stage maturity framework that evolves organizations from simple detection to autonomous remediation, supported by a reference architecture using open-source and cloud-native tools. Real-world use cases and data illustrate how this approach drastically reduces MTTR, improves service level agreement (SLA) compliance and minimizes human fatigue.
The Reliability Challenge in Cloud-Native Systems
Cloud-native architecture delivers unmatched scalability and flexibility, but it also introduces operational complexity, especially when dealing with observability gaps, deployment coordination and service interdependencies. In sprawling cloud environments, tracing the root cause of failure through fragmented logs and dashboards can take hours, significantly extending MTTR.

Multi-cloud adoption complicates visibility even further. Flexera’s 2024 State of the Cloud Report reveals that 89% of organizations now operate across multiple cloud providers, up from 87% last year, amplifying diagnostic blind spots across infrastructure layers cloudera.com+5Flexera+5SoftwareOne+5. This trend is echoed in a SoftwareOne recap, confirming the same statistic and its impact on organizational strategy.
Traditional alerting often relies on rigid, rule-based approaches, which generate noisy or irrelevant alerts. This forces SRE teams to chase false positives and switch between siloed dashboards during high-pressure incident response.
The complexity escalates when infrastructure spans AWS, Azure, GCP, on-prem and edge environments. A misconfigured rule, such as a restrictive security group in one availability zone, can trigger latency or disruption in another without clear telemetry.
On top of that, modern workloads are increasingly ephemeral. Containers and serverless functions can vanish before a human even starts triaging. AI-based observability tools can bridge these gaps by capturing transient telemetry, correlating context across domains and surfacing actionable insights in real time, thereby allowing teams to stay ahead of incidents rather than falling behind.
AI-Augmented Incident Lifecycle
Artificial intelligence (AI) does not just plug into a single point in the incident response process; it enhances every phase from detection to learning. From anomaly detection to postmortem analytics, AI offers SREs deeper contextual insights, suppresses alert noise and enables continuous improvement through a feedback-driven cycle.
The diagram below outlines the typical lifecycle of an incident and highlights where AI capabilities integrate.
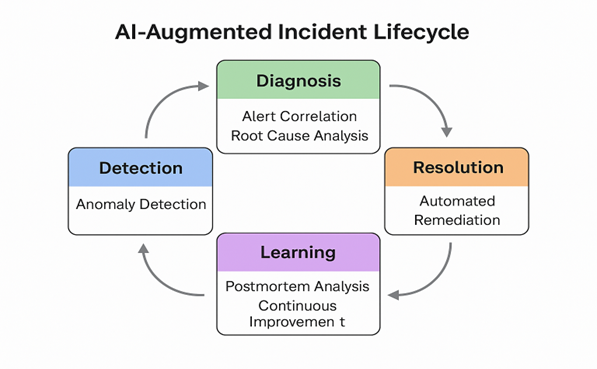
AI-Driven Incident Response: The Next Layer
AI for IT Operations (AIOps) offers tools to enhance observability and automate incident workflows. Core capabilities include:
- Time-Series Anomaly Detection: Models such as Prophet, Isolation Forest or Facebook Kats analyze metrics (e.g., CPU, memory and latency) to flag unusual behavior
- Event Correlation: Combines alerts from related components to reduce noise and create a unified incident view
- Root Cause Inference: Uses probabilistic reasoning or LLM-based summaries to suggest likely causes
- Automated Remediation: Triggers actions such as scaling pods, restarting services or rolling back deployments
Example Toolchain:
- Detection: Prometheus + Isolation Forest
- Correlation: OpenSearch ML, Splunk ITSI, Vector Databases
- Remediation: AWS Lambda, ArgoCD, PagerDuty, EventBridge
- Context Engines (Optional): Knowledge graphs or embeddings from RAG pipelines
This AI-enhanced stack reduces time per incident phase and builds confidence in repeatable response patterns. Organizations also benefit from better incident taxonomies and data to support proactive reliability strategies.
SRE Meets AI: Enhancing Reliability Engineering
SRE emphasizes service level indicators (SLIs), automation to reduce toil and blameless postmortems. AI extends these practices:
- Adding Context to SLIs: ML adds anomaly scores to SLIs, making error and latency measurements more meaningful.
- Reducing Toil: AI can automatically execute frequent tasks (e.g., pod restarts) within defined guardrails.
- Automating Root Cause Analysis (RCA): It automatically reconstructs incident timelines and surfaces probable root causes from logs and metrics.
- Enabling Proactive Capacity Planning: AI predicts future resource saturation and cost spikes using historical usage patterns.
This shift enables teams to respond to incidents in real time, allocate engineering time more effectively and improve system resilience. Companies are integrating LLMs into their RCA process, and for example, generating first-draft postmortems based on CloudWatch log sequences, or auto-summarizing RCA timelines via ChatGPT plugins. These tools help teams maintain detailed incident documentation without additional toil. In high-compliance industries, this AI-enhanced documentation aids audits and reduces the burden of manual RCA reporting.
More advanced teams are also building AI copilots for on-call engineers and chat-based tools that summarize incident timelines, suggest remediations and even simulate what-if scenarios to evaluate blast radius and response confidence.
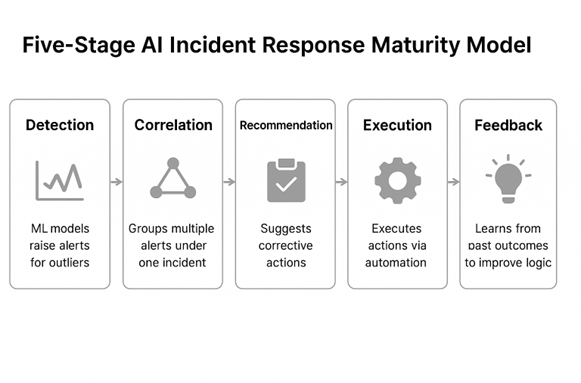
Five-Stage AI Incident Response Maturity Model
To adopt AI in incident response effectively, organizations need a clear path that balances automation with human oversight. The five-stage AI incident response maturity model provides a structured roadmap to evolve from manual operations to intelligent, self-healing systems while maintaining reliability, governance and cultural alignment.
Stage 1: Detection
Organizations start by applying ML models such as Isolation Forest, Facebook Prophet or Kmeans to observability data like Prometheus metrics. This phase focuses on reducing alert noise through pattern recognition and anomaly detection.
Stage 2: Correlation
AI systems are introduced to correlate alerts across services and infrastructure layers, creating unified incident views. For example, network latency, pod failures and spikes in 5xx errors can be grouped into a single root cause chain, significantly reducing investigation time.
Stage 3: Recommendation
AI-driven engines suggest contextual actions, such as restarting specific pods or rolling back deployments, based on past incidents and real-time telemetry.
Stage 4: Execution (Human-in-the-Loop)
At this stage, organizations introduce controlled automation. AI-generated actions are routed through approval workflows using tools such as Slack, Microsoft Teams or ChatOps. This ensures SRE teams remain in control while benefiting from faster, data-driven responses.
Stage 5: Feedback-Driven AI Remediation
This advanced stage closes the loop by continuously improving AI models. Systems learn from the outcomes of prior incidents, whether actions were effective or failed, and adapt accordingly. Postmortem data and alert outcomes are used to retrain anomaly detection thresholds and refine remediation playbooks.
For example, if an automated pod restart consistently resolves latency issues in a specific microservice, the platform can learn to auto-suggest or eventually auto-execute this fix with higher confidence and reduced human intervention.
To support this maturity journey on a scale, especially across distributed teams, a robust governance framework is essential. This framework typically includes:
- Defined ownership of AI models and automation logic, ensuring accountability for ongoing tuning and model health
- Version control and auditability for remediation scripts, alert rules and ML pipelines
- Ethical and safety guidelines that set boundaries for autonomous actions (e.g., no auto-scaling in production without a rollback fallback)
- Change management workflows to validate changes in sandbox environments before production deployment
For global organizations, governance must also address compliance boundaries, role-based access controls, data privacy regulations and regional SLA variances to ensure that automation aligns with business and regulatory requirements. This maturity path mirrors broader DevOps transformations: Incremental, measurable and rooted in cultural readiness. By aligning AI capabilities with SRE principles and operational rigor, organizations can evolve toward a future where systems are not only observable but also adaptive, resilient and intelligent by default.
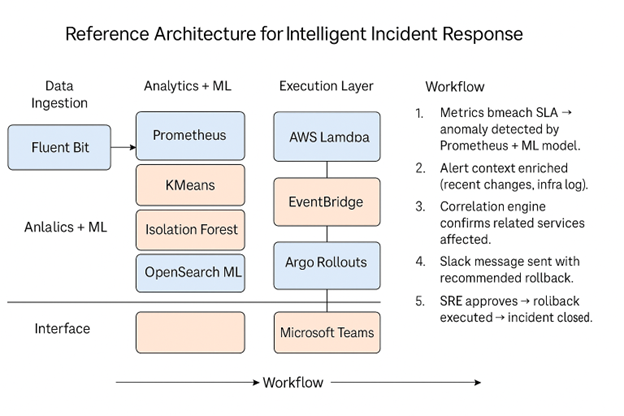
Reference Architecture for Intelligent Incident Response
A modular architecture can be deployed using open-source and managed cloud services.
Stack Overview:
- Data Ingestion: Fluent Bit, AWS CloudWatch
- Analytics + ML: Prometheus, KMeans, Isolation Forest, OpenSearch ML
- Execution Layer: AWS Lambda, EventBridge, Argo Rollouts, Step Functions
- Interface: Slack, Microsoft Teams (Notifications + Approvals)
By separating responsibilities into clear architectural layers, this model makes it easier to scale, test and innovate in specific areas without disrupting the entire workflow. For example, organizations can swap out an anomaly detection engine without having to redesign the remediation pipeline.
The following diagram illustrates the modular architecture and workflow components that support intelligent, AI-augmented incident response across ingestion, analysis, execution and interface layers.
Case Study: Incident Reduction at FinTrust
FinTrust, a global fintech company with real-time trading systems, experienced frequent alert storms during critical periods such as market opening hours. These surges in alerts overwhelmed on-call teams, delaying root cause analysis and leading to SLA breaches, especially when latency issues cascaded across dependent microservices.
Solution Strategy:
- Deployed ML-based anomaly detection on service latency metrics to identify outliers beyond static thresholds
- Used OpenSearch ML to correlate related incidents based on service topology and transaction spikes
- Introduced rollback triggers within ArgoCD pipelines, gated with Slack approval workflows for real-time intervention
Implementation Enhancements:
- Tuning the ML models required a month-long pilot phase where SREs labeled false positives to improve accuracy
- Developers adjusted service-level thresholds using SLO burn rates and Golden Signals to refine anomaly precision
- Cross-functional war rooms were replaced with Slack-based guided remediation prompts, reducing cognitive load
Impact:
- 85% reduction in MTTR, from an average of 22 minutes to under 4 minutes during peak windows
- 40% decrease in false positive alerts across core trading and payment systems
- SLA compliance improved from 93% to 99.7%, with zero missed SLAs over 90 days
Testimonial from FinTrust Ops Lead:
“Previously, our engineers sifted through fragmented dashboards and logs for over 30 minutes before taking action. Now, correlated alerts with context and suggested remediation steps are pushed to Slack, cutting our triage time by 70%. More importantly, our team feels confident in acting faster because the system earns their trust.”
This transformation extended beyond tooling. It involved:
- SRE leadership that creates a culture of psychological safety, encouraging experimentation with AI-based automation
- Executive sponsorship to support rollback automation in production environments
- Platform teams enabling continuous model retraining based on postmortems, feeding lessons into anomaly tuning pipelines
This case demonstrates how combining AI with human-aware workflows leads to sustainable, scalable improvements in high-stakes environments.
Implementation Recommendations:
For organizations exploring AI-driven incident response, the following implementation principles and phased roadmap provide a practical starting point for rollout.
- Start Small: Apply to one service with frequent incidents
- Use Existing Observability: Integrate ML with Prometheus or Datadog
- Human-in-the-loop: Always allow manual override
- Measure Everything: Track alert volume, MTTR and false positive rate
- Iterate Gradually: Expand maturity stages over quarters
- Ensure Data Quality and Governance: AIOps models are only as good as the data they consume. Invest in data cleanliness, consistent tagging and clear data governance policies to prevent ‘garbage in, garbage out’ scenarios
Recommended Roadmap for Adoption.
- Phase 1: Baseline setup
deploy Prometheus and Fluent Bit for metric/log ingestion. Enable anomaly detection via Isolation Forest.
- Phase 2: Automation layer
integrates AWS Lambda or Jenkins jobs for automated restarts or rollbacks.
- Phase 3: Human-in-the-loop reviews
connect approvals to Slack or Teams with action recommendations.
- Phase 4: Feedback and learning
automate postmortem summaries using OpenSearch or LLMs. Feed lessons into Prometheus alert tuning and, critically, feed these lessons and incident outcomes back into refining and retraining your AI models (e.g., improving anomaly detection thresholds, enhancing correlation rules or updating remediation playbooks).
Organizations should define measurable goals, such as reducing incident response time by 30% or improving first-response accuracy, before rollout. Periodic retrospectives ensure continued alignment with engineering goals and help validate AI contributions.
Future Outlook
As Gen AI and context-aware telemetry continue to evolve, SRE teams will benefit from proactive alerting systems that predict incidents before SLAs are breached. This includes forecasting saturation trends or spotting rogue deployments before they impact customers.
However, challenges remain: AI models can reflect training data biases or become opaque in decision-making. For regulated industries, auditability and explainability are essential. Therefore, future observability stacks must combine transparency with intelligence, blending AI insights with human accountability.
Emerging capabilities such as zero-shot incident classification or dynamic reliability scoring could offer next-generation insights into overall system health. As AIOps mature, SREs may act more as incident strategists than executors, focusing on systemic improvements over tactical firefighting.
By 2026, we anticipate that various SRE organizations will adopt hybrid workflows: AI recommends, humans approve, systems execute, with every step logged and explainable.
Looking ahead, the next critical role for SREs may center around ‘AI reliability engineering’: Ensuring the quality, fairness and transparency of AI-driven incident response systems. This includes tuning model behavior, validating remediation policies and designing fallback mechanisms for edge cases where human judgment is irreplaceable. SREs will also be instrumental in architecting governance frameworks, overseeing responsible AI usage in production environments.
Conclusion
Integrating AI into incident response isn’t about replacing SREs; it’s about elevating their ability to manage complexity and scale reliability. By embedding AI across the incident lifecycle, from anomaly detection and alert correlation to guided remediation and continuous learning, teams can shift from reactive firefighting to proactive resilience.
This article outlines a deliberate, phased approach to AI integration that supports cultural adoption, reinforces trust through human-in-the-loop safeguards and delivers measurable improvements in MTTR, alert fatigue and SLA compliance. These patterns are not hypothetical; they’re grounded in real-world deployments across high-stakes environments.
However, this journey demands more than just tools. Success hinges on clean data, thoughtful governance, cross-functional alignment and psychological safety for teams to experiment and adapt. As AI capabilities mature, the role of the SRE will evolve from incident responder to designer of autonomous, resilient systems.
In regulated or mission-critical domains such as finance and healthcare, the ability to explain and audit AI-driven decisions will become just as important as reducing response times. Ensuring transparency, traceability and ethical guardrails must be embedded from day one.
The future of incident response is not just automated, it’s accountable, adaptive and guided by engineering judgement. When AI augments, not replaces, human insight, organizations unlock a new era of intelligent, explainable and trustworthy reliability operations.
Those who lead this shift will redefine how modern infrastructure is operated, building systems that not only recover faster but also continuously learn, improve and scale with confidence.
Takeaways
- AI-driven incident response frameworks help reduce mean time to recovery (MTTR) by intelligently detecting, correlating and remediating cloud-native infrastructure incidents in real time.
- The integration of site reliability engineering (SRE) principles and machine learning (ML) fosters a shift from reactive to proactive reliability management on a scale.
- A five-stage maturity model enables organizations to gradually adopt automation while maintaining human control over critical operations.
- A modular architecture built on open-source and cloud-native tools such as Prometheus, AWS Lambda and ArgoCD provides practical implementation guidance.
- Real-world deployments in financial and SaaS platforms have shown significant reductions in alert fatigue, resolution time and operational overhead.
