
Confluent Makes Deploying Kafka on Kubernetes Easier
Confluent has extended its reach by making it possible to deploy a curated instance of the open source Kafka distributed event streaming software on top of a Kubernetes environment running in an on-premises IT environment.
Rohit Bakhshi, product manager at Confluent, says Confluent for Kubernetes is based on the same platform the company employs today to make Kafka available as a cloud service. Using a declarative application programming interface (API), an IT team can now declaratively deploy both Kafka and the Kubernetes cluster on which it runs in an on-premises environment or edge computing platform, notes Bakhshi.

That infrastructure-as-code approach makes use of Kubernetes APIs to provide a layer of abstraction for deploying Kafka on Kubernetes without requiring IT teams to master all the nuances of deploying a cluster environment, adds Bakhshi.
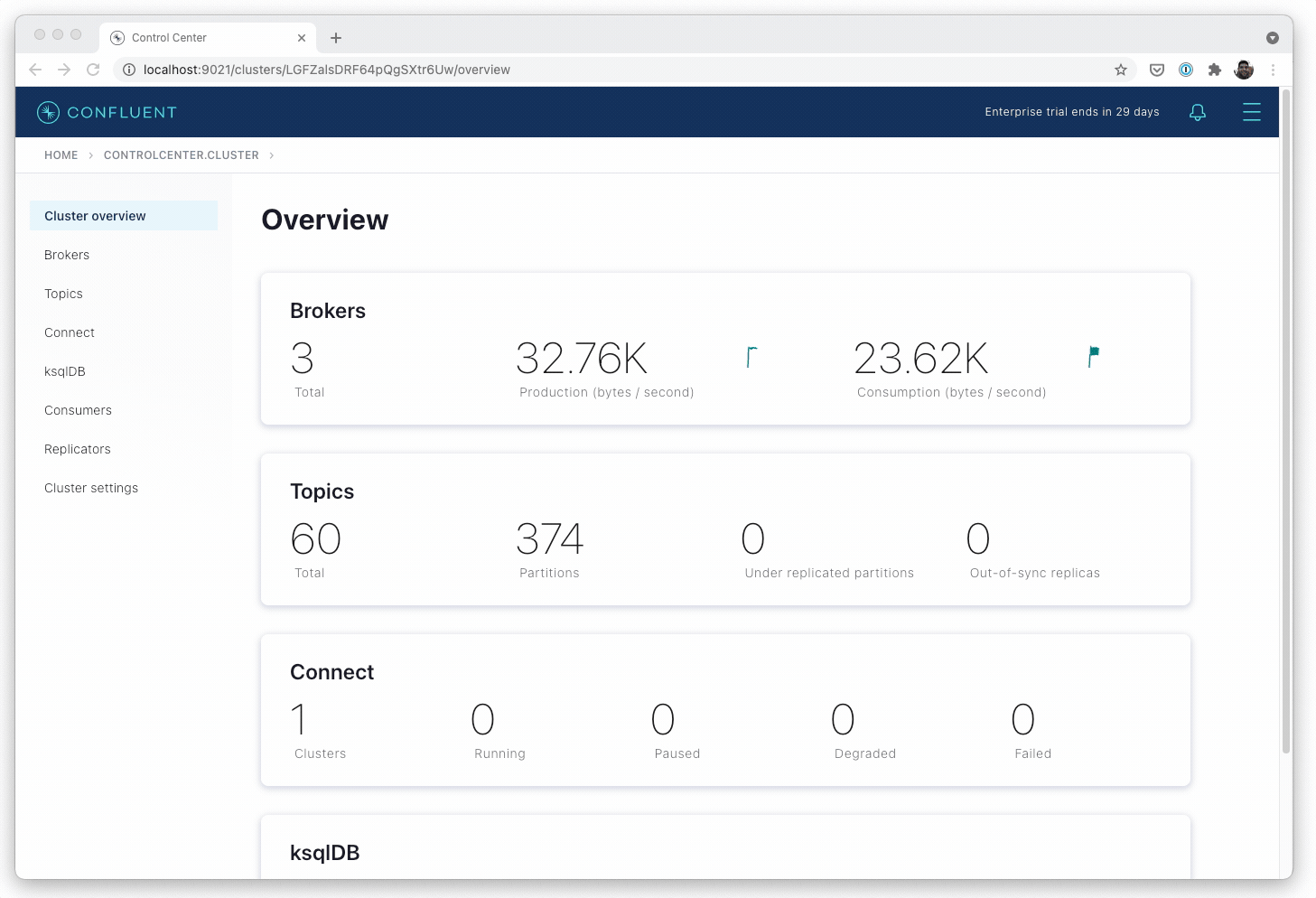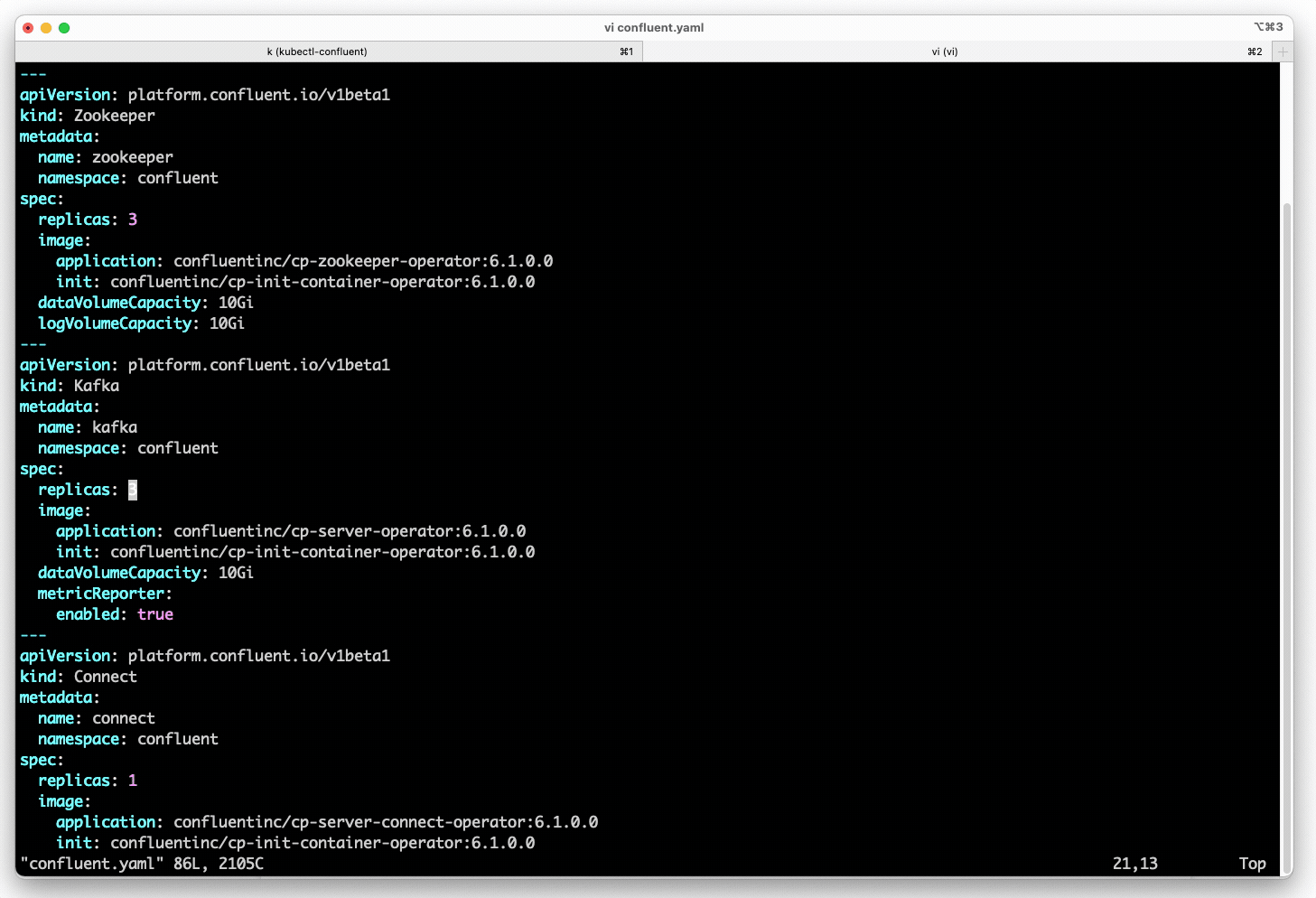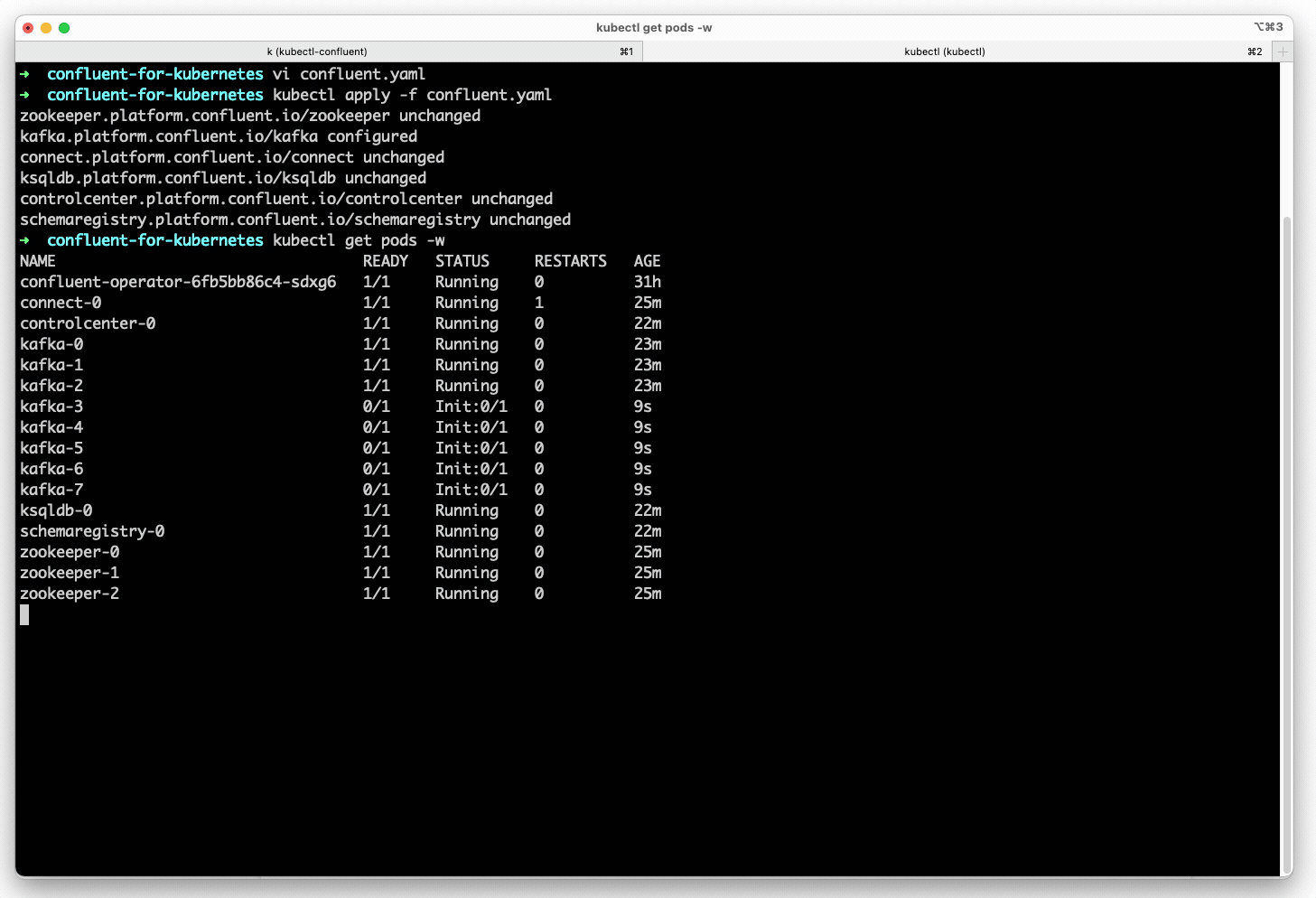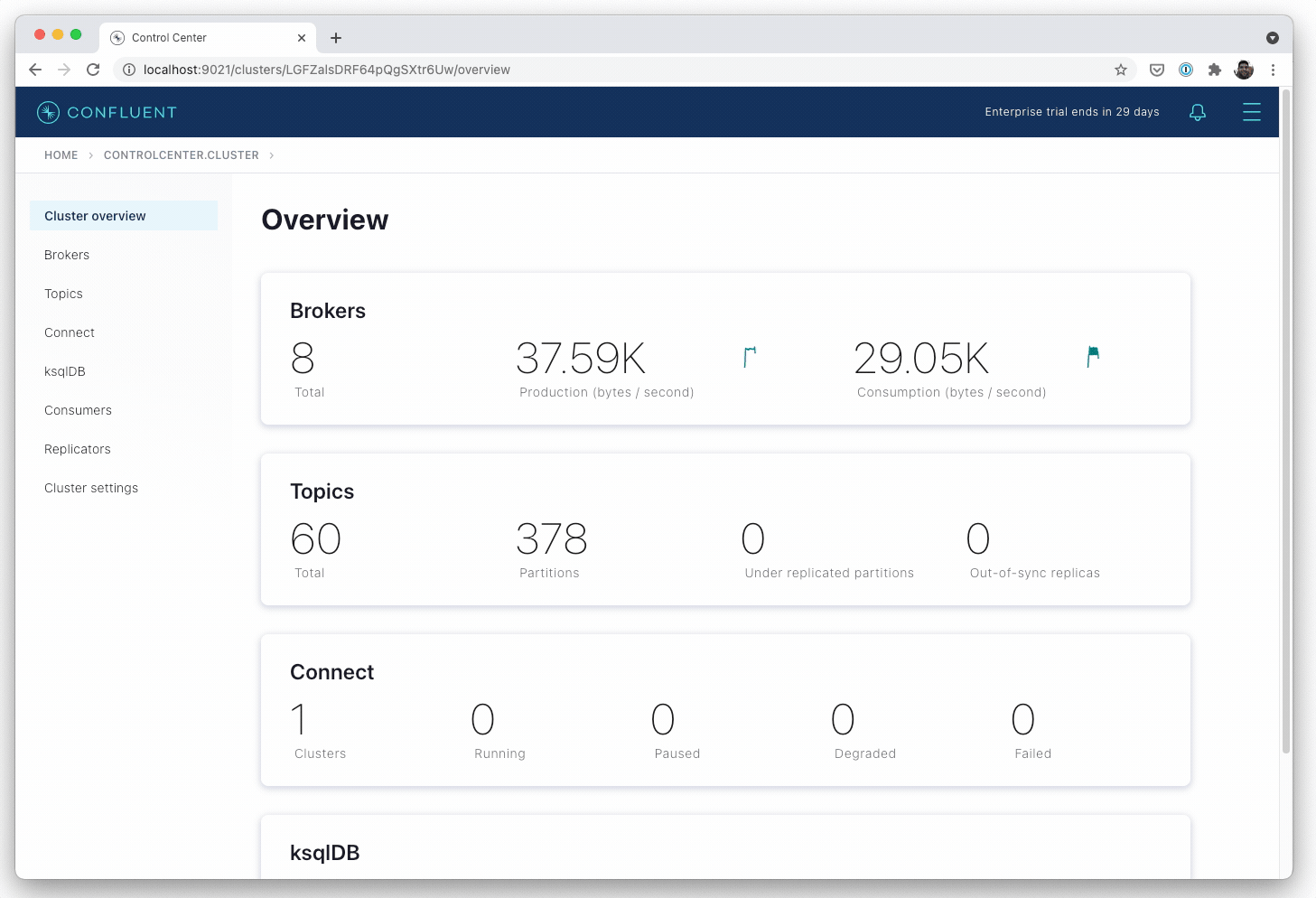
As IT environments continue to evolve, there is a high correlation between adoption of Kafka and Kubernetes. Kafka makes it possible to analyze streaming data in motion, which is a critical capability for most digital business processes. Kubernetes, meanwhile, makes it possible to deploy Kafka on any platform an IT organization sees fit.
Confluent for Kubernetes also detects if a process fails, and will automatically restart processes or reschedule them as necessary. Automated rack awareness also spreads replicas of a partition across different racks, improving the availability of brokers and limiting the risk of data loss. The platform will also automatically generate configurations, schedule and run new broker processes and ensure data is balanced across brokers. The goal is to make is simpler to deploy Kafka as much as it is Kubernetes, notes Bakhshi.
Arguably, the one thing the two platforms have in common is that both Kafka and Kubernetes are often viewed as complex infrastructure that requires a lot of specialized expertise to deploy and master, especially as IT environments become more distributed. Making Kafka easier to deploy on top of Kubernetes is a first step toward making both platforms more accessible.
In the meantime, the way data is being processed within organizations is shifting rapidly. Rather than collecting data at an endpoint that is then transferred to an application to process it in batch mode, organizations are shifting to processing data in near-real-time as close to the point where data is being created and consumed as possible. Kafka provides a mechanism to also analyze streaming data in transit alongside Kubernetes clusters that have the compute and storage horsepower needed to process data at the network edge. The aggregated analytics generated can then be shared with backend applications in a way that reduces the volume of data that needs to be transferred across a wide area network to be processed by a batch-oriented analytics application running in either a data warehouse or a data lake in the cloud.
It’s clear enterprise computing is in the process of being utterly transformed. The challenge now is making sure the rest of the IT organization appreciates the full implications of that transition.
