
Java Code Isn’t the Problem – The Container Is
For a long time, our container security process felt good enough. Not great, but good enough.
Before each release, someone on the team would run a scan, glance through the report, fix a few high-severity issues, and move on. The rest usually ended up in a backlog that no one really prioritized. It wasn’t perfect, but nothing was visibly breaking, so we kept going.

That changed during what should have been a routine deployment of one of our Java services. It was a fairly standard setup, Spring Boot, packaged as a JAR, running inside a Docker container. No major code changes, just a version bump and a fresh build. I still remember staring at that report, thinking something must be wrong with the scan itself. There were dozens of vulnerabilities, and most of them had nothing to do with the code we had just written.
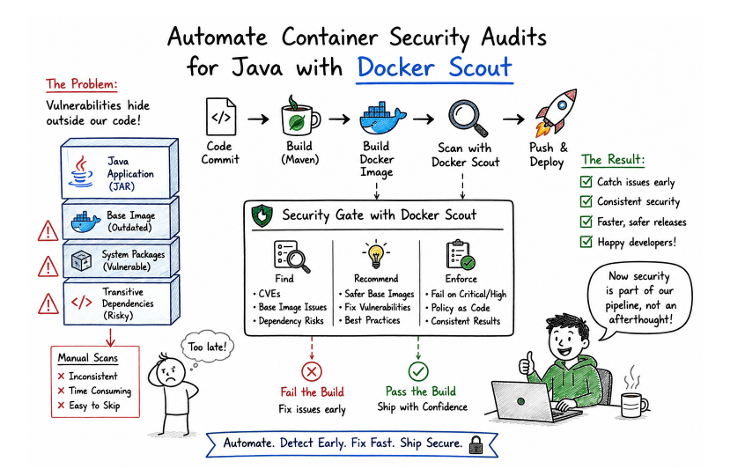
At first, it didn’t make sense. We hadn’t introduced risky libraries. The business logic hadn’t changed. But the deeper we looked, the clearer it became that the problem wasn’t in our Java code at all. It was in everything surrounding it. The base image we were using had outdated packages. Some of the transitive dependencies pulled in through Maven were no longer safe. Even parts of the container layers we never thought about were contributing to the issue.
That was a bit of a wake-up call. We realized we had been focusing almost entirely on application-level security, while the container itself – where the application actually runs- was quietly accumulating risk over time.
Our first instinct was to tighten the process. Run scans more often. Assign someone to review them more carefully. Maybe track vulnerabilities more strictly in tickets. It helped a little, but it didn’t really solve the problem. The process was still manual, and anything manual eventually gets skipped, delayed, or deprioritized when deadlines get tight.
What we really needed was something that would just happen automatically, without relying on someone remembering to do it.
That’s when we started using Docker Scout. At first, we treated it as another tool to run locally, but it quickly became clear that the real value lay in integrating it into the build process itself. So we wired it into our CI pipeline. Every time a Java service was built, the container image was scanned as part of the workflow. If there were critical vulnerabilities, the build failed. No discussions, no exceptions.
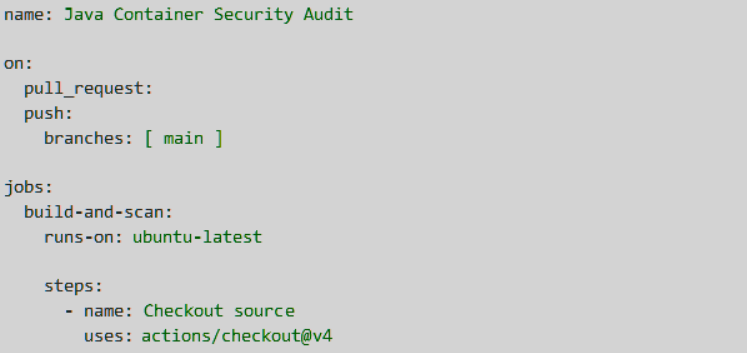
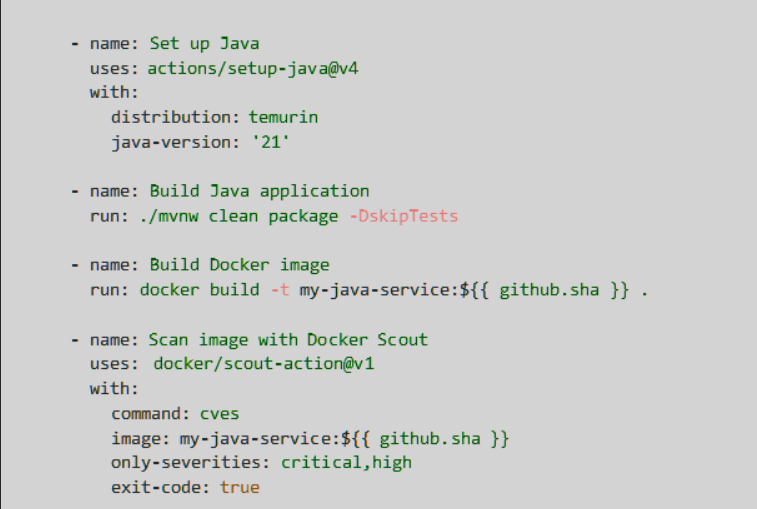
For GitHub Actions, the first version looked something like this. It built the Java service, created the Docker image, and then stopped the pipeline if Docker Scout found critical vulnerabilities.
Docker’s official CI docs support using Docker Scout in GitHub Actions and Jenkins pipelines.
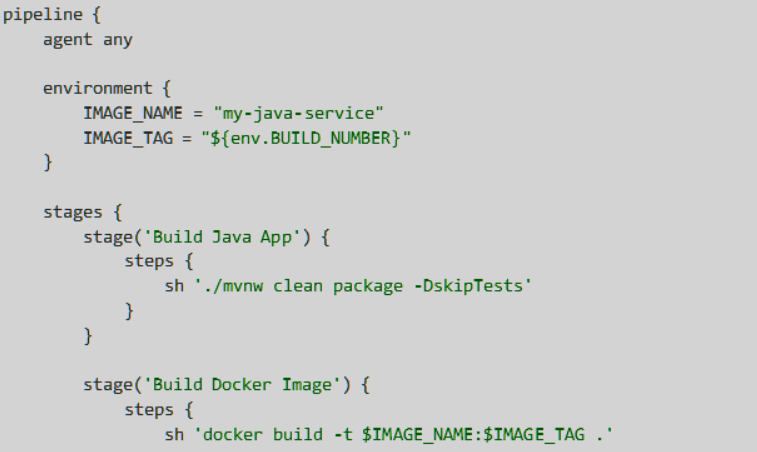
For Jenkins, we used the same idea. The important part was not the tool choice; it was the gate. If the image had critical or high vulnerabilities, the build failed before the release moved forward.
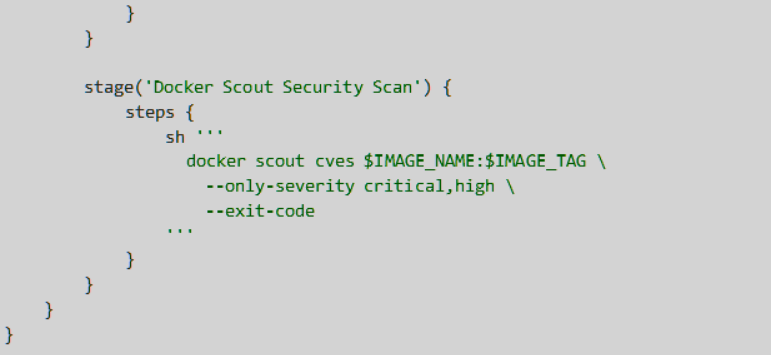
That small pipeline gate changed the conversation. A vulnerability report was no longer something someone reviewed after the release meeting. It became part of the build result. If the image was unsafe, the pipeline said so immediately, and the team fixed it while the change was still fresh in their mind.
We also started treating base images differently. Earlier, they were just a starting point, something you pick once and forget. But now we have begun tracking them more deliberately, the same way we track Java dependencies. If a newer, more secure version of a base image was available, we made it part of our upgrade cycle. That alone reduced a significant portion of the vulnerabilities we were seeing.
Another small but important change was where we exposed the results. Instead of burying reports in dashboards, we made sure the output showed up directly in CI logs and pull requests. Developers didn’t have to go looking for issues. They were right there, next to their code changes. It made the feedback immediate and hard to ignore.
Over time, we also started relying on the tool’s suggestions to guide fixes. When it pointed to safer base images or flagged vulnerable dependencies, we used that information to update our builds. In some cases, we automated parts of this using Maven tooling, just to reduce the friction.
Within a few weeks, things started to feel different. Releases became more predictable. Fewer surprises showed up late in the cycle. Fixes happened earlier, when they were easier to handle. But more than anything, the mindset changed. Security was no longer a separate step; it became part of how we built and shipped software.
Looking back, the most interesting part is that our Java code was never really the problem. We were writing solid services. The issue was that we assumed security stopped at the application layer, when in reality, a big part of the risk lives in the environment the application runs in. The container, the base image, the dependencies, those layers matter just as much.
If you’re building Java services in containers today, this is probably worth thinking about. It’s easy to focus on code quality, performance, and architecture, and those things do matter. But unless you’re continuously scanning and managing what’s inside your container, you’re only seeing part of the picture.
For us, the shift wasn’t about adopting a new tool. It was about changing when and where we think about security. Once it became part of the build process instead of an afterthought, everything else followed naturally. And honestly, it made shipping releases a lot less stressful.
