
When Microservices Fall Short
Microservices principles are used to decouple different business domains through a bounded context. We can develop microservices independently to benefit from polygot architecture. But microservices architecture is not completely able to solve the problem of decoupling business logic with middleware. If the middleware acts as a library contained in microservices, then this coupling becomes very obvious. With more distributed technologies, we need to make the relationship between microservices and integration platforms more coupled. The problem of managing state across microservices remains a pain point, as well.
Falling back to traditional single middleware (for example, ESB), provides all the necessary technical functions. But it lacks the agility that the current business landscape requires.

The Ability to Adapt and Expand
That’s why, behind most microservices-based architectures, you’ll find containers and Kubernetes. This problem is being solved with a multi-runtime applications architecture, also known as Mecha architecture. Enterprises are now capable of developing microservices by moving all the traditional middleware functions to the platform and ready-made secondary runtime.
Kubernetes and containers made a huge technological leap in the life cycle of multilingual applications and laid the foundation for future innovation. Service grid technology, through advanced network functions in Kubernetes, improved and advanced applications.
During this evolution, solutions like Knative focus mainly on serverless workloads through rapid expansions. Knative also meets the requirements of service choreography and event-driven binding.
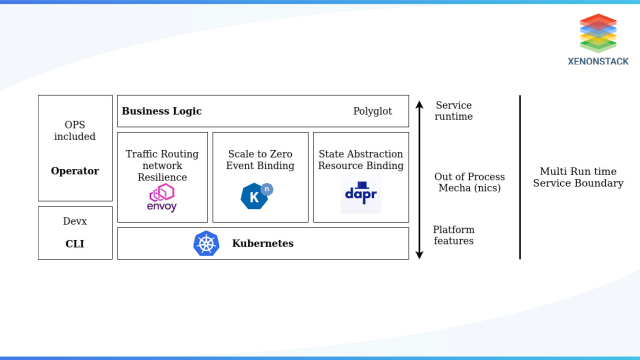
The above diagram illustrates how, in the future, we will use multiple runtimes to implement a distributed system. Multiple runtimes do not mean there will be multiple microservices; instead, it means each microservice will be made up of multiple runtimes.
Let’s explore micrologic and some features of this new runtime environment.
Micrologic itself is not a microservice. It just contains the business logic that the microservice will have. But this logic can only be related to the Mecha component in combination. On the other hand, microservices are self-contained and don’t take part in the overall function. The combination of both micrologic and Mecha forms a microservice.
This is not the same as functional or serverless architecture. A serverless architecture functions to implement a single operation, because this is the unit of scalability. In this regard, the function is different than that of realizing multiple operations micrologic, but the implementation is not end-to-end. Most important of all, the implementation of the operation is distributed in Mecha and micrologic.
In micrologic, the user code does not interact with other systems and no distributed system primitive will be implemented. It passes two-factor standards (i.e HTTP/grpc, CloudEvents standard) and Mecha conducts the interaction.
Also, Mecha uses rich functions and communicates with other systems under the guidance of the configuration steps mechanism. Micrologic is only responsible for implementing business logic separated from distributed system problems.
Mecha is a universal, highly configurable, reusable component and provides distributed primitives as out-of-the-box functionality. In Mecha, every instance must be configured with micrologic components.
Mecha, in correct micrologic, the runtime makes any assumptions. It works with open protocols and formats (HTTP, gRPC, JSON). Mecha can be used with multi-language microservices or even with single-chip systems.
In simple text format such as YAML and JSON, Mecha can declaratively configure. This format indicates which features to enable and how to bind them to a micrologic endpoint. For professional API interactions, it can serve as an additional specification, for example, OpenAPI and ASYNCAPI. For a stateful workflow composed of multiple processing steps, you can use things like Amazon state language. The key point here is it’s easy to do without coding using text-based declaratives – the definition of multilingual.
Please note that these are futuristic predictions; at present, it has not been used for state choreography or EIP of Mecha, but I hope the existing Mecha (Envoy, Dapr, Cloudstate, etc) will start adding this kind of feature soon. Mecha is a distributed primitive abstraction layer at the application level.
Instead of relying on multiple agents for different purposes (for example, network agent, caching proxy, binding agent), it’s better to use one Mecha to provide all of these functions. The implementation of some functions, such as storage, message persistence, cache, etc., will be inserted and supported by other cloud or local services.
Benefits of Mecha Architecture
The advantage of Mecha architecture is the loose coupling between business logic and more and more distributed system components. These two elements of software have completely different dynamics. Business logic is the only custom code written internally. It often changes, and depends on your organizational priorities and execution capabilities. On the other hand, distributed primitives solve these business problem. These are well-known and developed by software vendors. The code is based on the priority of the supplier, release cycle, security patch and open source control rule.
This also provides a better way for technology platform vendors to distribute complex middleware software. As long as the interaction with middleware involves openness, API and standard interprocess communication, software vendors are free to release patches and upgrade at their own pace. Consumers are free to use the language, library, runtime deployment methods, etc. they like to use.
