
Together AI Adds Container Inference to Managed Service for AI Models
Together AI today added a container interface for inference to it managed cloud service it provides for deploying artificial intelligence (AI) models.
Nikitha Suryadevara, product lead for inference at Together AI, said the Dedicated Container Inference service will make it simpler for organizations that are deploying AI models, for example, generating videos or audio to deploy them without having to be concerned about what underlying IT infrastructure is being used. In effect, all the IT team will need to do to run AI inference workloads is to encapsulate their runtime, dependencies, and inference code for the AI model in a Docker container, she said.

Together AI makes available a managed cloud service based on graphical processor units (GPUs) through which it provides replicas, handles networking, health checks, and monitoring.
The Dedicated Container Inference service is designed to be used mainly for AI models that lend themselves to being encapsulated in a container because they include custom code, models or inference engines.
For large models that require multiple GPUs, Together AI also provides built-in support for distributed inference via the torchrun console script written in PyTorch.
Additionally, Together AI provides support for volume mounts, which enables IT teams to upload model weight once versus having to rebuild, for example, a 50GB container every time a model weight is updated.
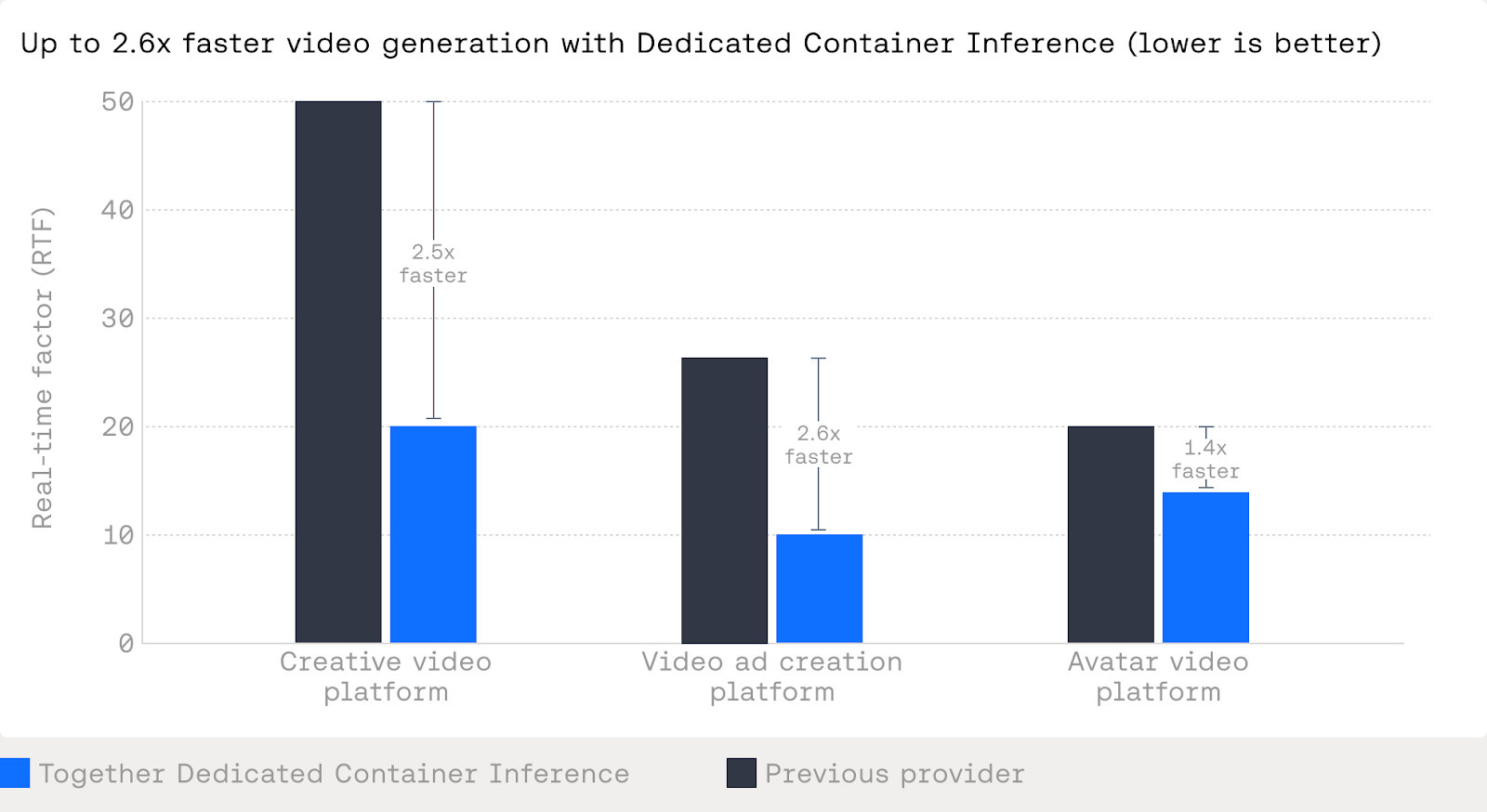
Overall, containerized models running on the Together AI platform will generally run faster than on other platforms, said Suryadevara.
Most of the existing Together AI customers are AI native in the sense that they are only running AI applications, said Suryadevara. However, responsibility for deploying inference engines within enterprise organizations is shifting toward internal IT teams as they deploy more custom AI applications in production environments. Together AI now provides an alternative for deploying AI inference engines for certain classes of AI models versus as an alternative to requiring an IT team to acquire and provision on-premises IT infrastructure.
There is, of course, now no shortage of options when it comes to building AI applications. The challenge and the opportunity is finding a way to make various AI models accessible to the average application developer without locking organizations into a specific platform, which is one reason many organizations deploying AI workloads have embraced containers.
That approach also enables IT organizations to then take advantage of Kubernetes to dynamically scale those workloads up and down as required. A recent Cloud Native Computing Foundation (CNCF) survey found two-thirds (66%) of respondents reporting their organization is hosting either all of their (23%) or some of their AI inference workloads (43%) on Kubernetes clusters.
Each organization will need to determine for itself to what degree to manage training and inference AI models together or shift responsibility for the latter more towards an internal IT department. Regardless of approach, the one thing that is certain is that it continues to be challenging for internal IT teams to acquire platforms that have GPUs that continue to be scarce, given the demand currently being generated by cloud service providers. A managed service provides an alternative approach where the pressure to acquire GPUs cost-effectively falls mainly on the managed service provider. All the internal IT team then needs to worry about is making sure the containers used to deploy any AI model can be easily updated as needed.
