
Komodor Adds Ability to Automatically Remediate Kubernetes Configuration Drift
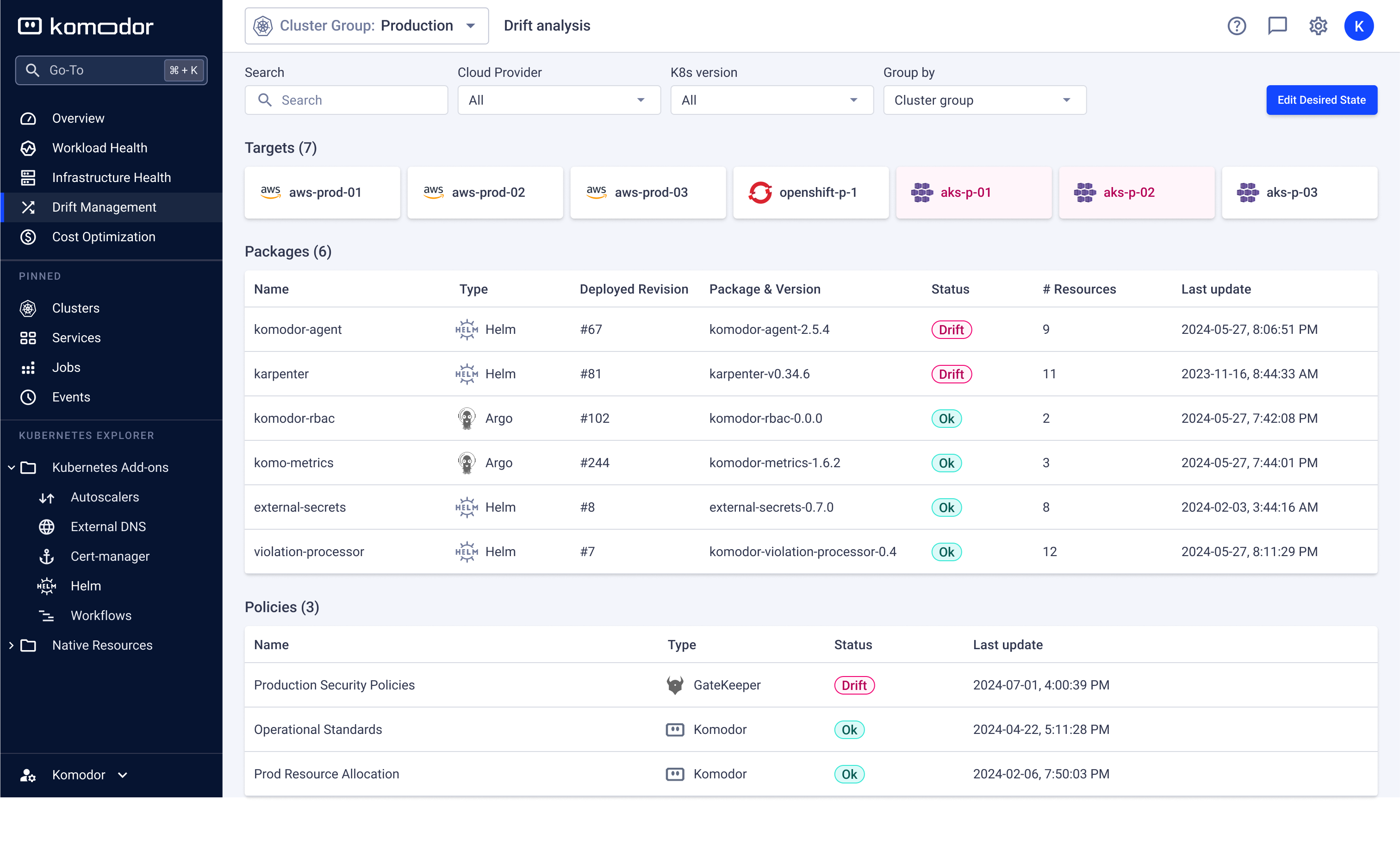
Komodor today added the ability to detect and remediate configuration drift across a fleet of Kubernetes clusters.
Company CTO Itiel Shwartz said this extension of the company’s namesake platform for managing Kubernetes clusters makes it possible to automatically restore baseline configurations that would otherwise require hours to manually restore.

The root causes of configuration drift are usually attributable to manual changes that overrode previous configurations made using infrastructure-as-code (IaC) tools, versions of Helm charts that created an inconsistency between clusters, or outdated container images running in production due to incomplete rollouts
Those changes can result in misconfigured deployments causing memory limits or CPU throttling, compliance issues, or, worst of all, potential outages.
The Komodor platform now instantly flags deviations from expected configurations by enabling IT teams to visually compare versions and resource allocations made using Helm charts or GitOps-managed configurations.
The overall goal is to make it simpler for IT organizations to manage fleets of Kubernetes clusters that are being increasingly deployed across highly distributed computing environments, said Shwartz.
 While Kubernetes clusters remain challenging to manage, more organizations are relying on platforms such as Komodor to manage them at higher levels of abstraction.
While Kubernetes clusters remain challenging to manage, more organizations are relying on platforms such as Komodor to manage them at higher levels of abstraction.
Additionally, artificial intelligence (AI) agents will increasingly discover issues that they, with the approval of an IT team, automatically remediate. Komodor, for example, last year made available a generative artificial intelligence (AI) agent, dubbed Klaudia, to its platform.
The overall goal is to make managing Kubernetes environments more accessible to a wider range of IT administrators who might not have the programming expertise required to manage the YAML files used to configure clusters. In the absence of those capabilities, it simply becomes too easy to misconfigure a Kubernetes cluster.
Despite existing management challenges, organizations continue to invest in building and deploying cloud-native applications. A recent Futurum Research survey found 61% of respondents are using Kubernetes clusters to run some (41%) or most (19%) of their production workloads. The top workloads deployed on Kubernetes are AI/ML/Generative AI (56%) and data-intensive workloads such as analytics, tied at 56% each, closely followed by databases (54%), modernized legacy applications (48%) and microservices-based applications (45%).
The challenge, as always, is endeavoring to make sure the Kubernetes clusters deployed are running the latest version of the orchestration of the platform. Many organizations are not only running much older versions of Kubernetes; they are also maintaining multiple distributions provided by two or more different vendors.
Too many of the IT teams managing those clusters have also yet to shift their mentality away from managing monolithic applications running on virtual machines, noted Shwartz. Kubernetes environments running cloud-native applications are much more frequently updated, leading to a host of different management challenges, he added.
One way or another, of course, it’s only a matter of time before more IT teams come to grips with Kubernetes clusters as the number of cloud-native applications being deployed in production environments continues to increase. The only issue left to determine is the level of programming expertise that will be needed for them to achieve that goal.
