
Causely Adds MCP Server to Causal AI Platform for Troubleshooting Kubernetes Environments
Causely today unveiled a Model Context Protocol (MCP) server that enables developers to automatically diagnose, understand, and remediate complex issues within Kubernetes and application code using natural language prompts from within their integrated developer environment (IDE).
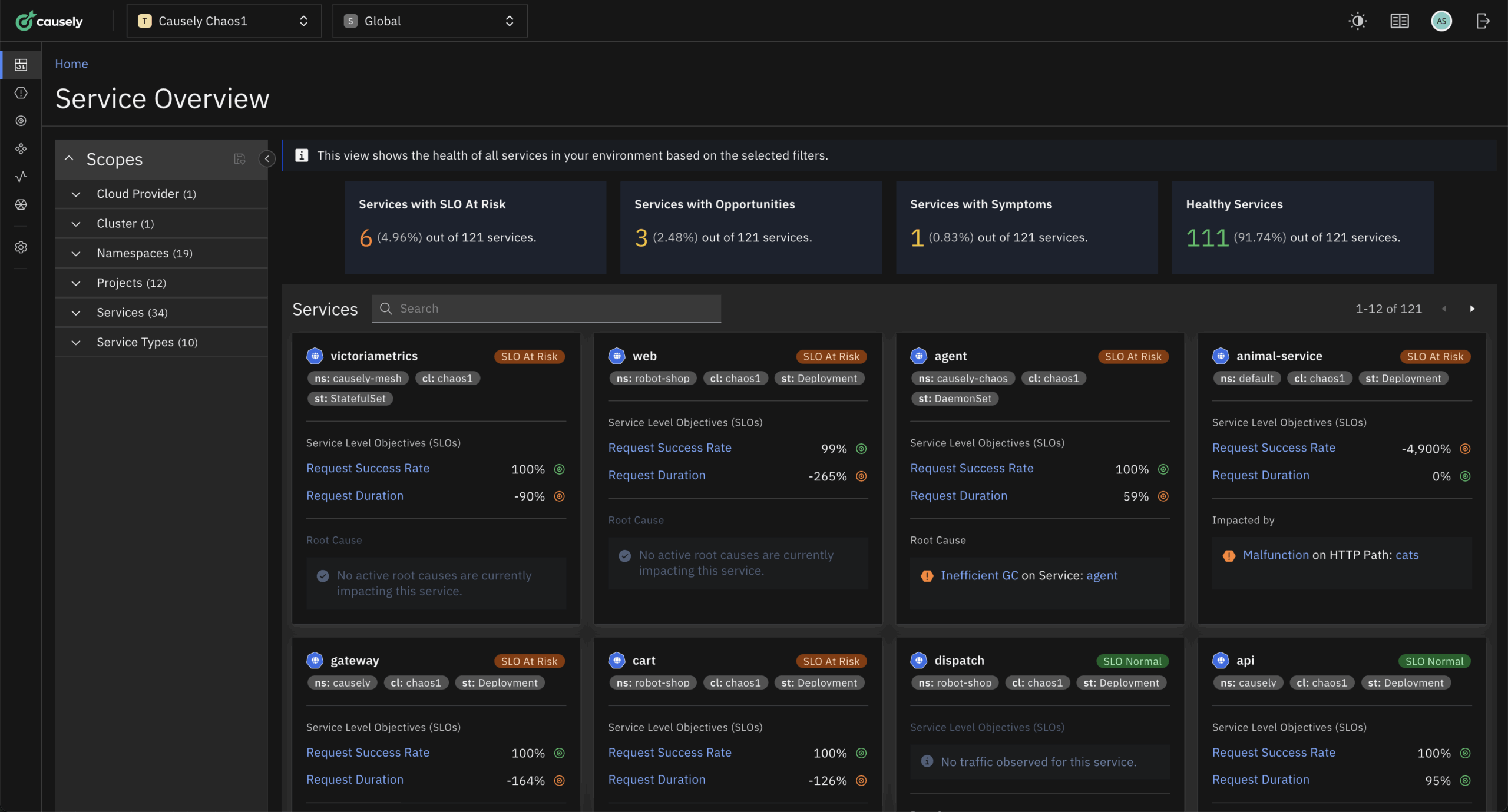
Severin Neumann, head of community for Causely, said the Causely MCP Server will make it easier for application developers to troubleshoot Kubernetes issues using a platform that already uses causal artificial intelligence (AI) models that were created to augment site reliability engineers (SREs).

The overall goal is to provide developers and SREs with insights needed to reduce downtime by analyzing the state of the system in real time to identify whether the cause of an issue is in the infrastructure or application layer. The Causely platform will then recommend precise code, configuration or Helm chart changes for developers to review, refine, or approve within their IDE.
Additionally, the Causely platform will also generate patches for Terraform, Helm, or application code to prevent issues from recurring.
It’s not clear at this point just how many software engineering teams are relying on AI to automate the management of Kubernetes workflows, but given the complexity of these environments, there is a significant opportunity to reduce stress and toil. The simple truth is that many organizations are limiting the number of Kubernetes clusters they might deploy simply because there isn’t enough SRE expertise available to manage them.
Many developers, meanwhile, have historically been intimidated by the complexity of Kubernetes clusters. The MCP server developed by Causely makes it simpler for developers to resolve issues on their own, both before and after cloud-native applications are deployed.
It’s not likely AI platforms such as Causely will replace the need for SREs any time soon, but they do present an opportunity for fewer SREs to successfully manage a larger number of Kubernetes clusters at scale at a time when the number of cloud-native applications being deployed continues to steadily increase. The issue, as always, is reducing mean time to remediation whenever all but inevitable incidents occur.
In fact, AI advances should enable SREs to spend more time on strategic issues such as ensuring availability versus constantly performing tactical incident management tasks, said Neumann.
Ultimately, multiple AI models that are being invoked by AI agents will soon be pervasively embedded across every DevOps workflow. The next major challenge will be finding a way to orchestrate the management of AI agents that will be accessing causal, predictive and generative AI models to optimize IT environments. Hopefully, those advances will significantly reduce the level of burnout that many software engineering teams experience as they are overwhelmed by repetitive manual tasks, especially when managing complex Kubernetes clusters that can be easily misconfigured.
In fact, it’s even conceivable that as AI starts to eliminate many of the bottlenecks that exist in software engineering workflows, much of the joy that attracted SREs and application developers to IT in the first place might soon be rediscovered.
