
Running Kubernetes in Production: Practical Lessons From the Field
Kubernetes has become the de facto platform for running containerized workloads at scale. While spinning up a cluster is relatively straightforward, operating Kubernetes reliably in production is far more challenging. Teams often encounter issues related to scalability, security, observability and day-two operations that are rarely discussed in quick-start guides.
This article shares practical, production-focused lessons learned while running Kubernetes in real-world environments, with an emphasis on reliability, security and operational clarity.

Understanding Kubernetes Beyond Pods and Services
Kubernetes is more than a container scheduler. In production, it becomes a distributed system responsible for workload orchestration, networking, security boundaries and resource management.
Various operational problems arise when teams treat Kubernetes as a black box. Understanding how components such as the API server, scheduler and controllers interact helps engineers troubleshoot issues such as delayed pod scheduling, unexpected restarts or resource starvation.
A strong mental model of Kubernetes internals reduces reliance on guesswork and speeds up incident resolution.
Designing Resilient Workloads With Resource Management
One of the most common production issues in Kubernetes is improper resource allocation. Without explicit CPU and memory limits, workloads can consume more resources than expected, impacting cluster stability.
Defining resource requests and limits ensures predictable scheduling and protects the cluster from noisy neighbors.

This simple configuration dramatically improves workload stability and makes capacity planning more reliable.
Handling Configuration Safely Using ConfigMaps and Secrets
Hard-coded configuration values are a frequent source of deployment errors. Kubernetes provides ConfigMaps and Secrets to separate configuration from application code.
Using externalized configuration allows teams to update behavior without rebuilding images and reduces the risk of leaking sensitive information.
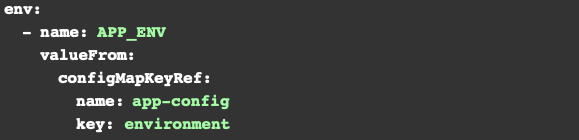
This approach simplifies environment promotion and improves security posture across clusters.
Improving Availability With Health Probes
Kubernetes relies heavily on health probes to manage application life cycle. Without properly defined liveness and readiness probes, the platform cannot make informed decisions about restarting or routing traffic.
Readiness probes prevent traffic from reaching unhealthy pods, while liveness probes help Kubernetes recover from stuck applications.

Well-designed probes significantly reduce downtime during deployments and failures.
Observability: Seeing What the Cluster Is Doing
Production Kubernetes clusters generate a large volume of signals. Without observability, diagnosing issues becomes time-consuming and error-prone.
Effective observability includes:
- Centralized logging
- Metrics for nodes, pods and applications
- Alerts based on symptoms, not noise
By instrumenting workloads and monitoring cluster behavior, teams can detect issues early and respond with confidence.
Securing Kubernetes With Least Privilege
Security incidents in Kubernetes often stem from overly permissive access. Role-based access control (RBAC) enables fine-grained permissions that limit what users and workloads can do.

Applying least-privilege principles reduces blast radius and helps organizations meet compliance requirements without sacrificing agility.
Managing Deployments With Rolling Updates
Zero-downtime deployments require careful rollout strategies. Kubernetes supports rolling updates that gradually replace old pods with new ones.
By tuning deployment strategies, teams can balance speed with safety and avoid service interruptions during releases.

This ensures that capacity remains available while updates are in progress.
A Real-World Lesson: Node Pressure and Pod Evictions
In one production environment, a sudden increase in traffic caused memory pressure on multiple nodes. As several workloads lacked memory limits, the kubelet began evicting pods unpredictably, impacting unrelated services.
The fix was not adding more nodes — but defining proper resource limits, monitoring eviction metrics and adjusting autoscaling thresholds. Once corrected, the cluster stabilized without additional infrastructure cost.
Conclusion
Running Kubernetes in production is as much an operational discipline as it is a technical challenge. Success depends on understanding the platform, designing resilient workloads, enforcing security boundaries and maintaining visibility into cluster behavior.
By treating Kubernetes as a critical production system and applying best practices consistently, teams can unlock its full potential and operate with confidence at scale.
